Кто такой дата-сайентист
Содержание:
- Образование. Шесть шагов на пути к Data Scientist
- Математика для анализа данных от онлайн-университета «Нетология»
- Data Scientist: кто это и что он делает
- Как стать Data Scientist с нуля?
- Уровень 1. От стажёра к джуну
- Как различаются роли дата-инженеров и дата-сайентистов
- Теория
- Уровень 2. От джуна к мидлу
- Дата-сайентисты в облаках
- Как выглядит его рабочий день?
- В каких случаях становятся специалистом по Data Science?
- Как он это делает?
Образование. Шесть шагов на пути к Data Scientist
Путь к этой профессии труден: невозможно овладеть всеми инструментами за месяц или даже год. Придётся постоянно учиться, делать маленькие шаги каждый день, ошибаться и пытаться вновь.
Шаг 1. Статистика, математика, линейная алгебра
Для серьезного понимания Data Science понадобится фундаментальный курс по теории вероятностей (математический анализ как необходимый инструмент в теории вероятностей), линейной алгебре и математической статистике.
Фундаментальные математические знания важны, чтобы анализировать результаты применения алгоритмов обработки данных. Сильные инженеры в машинном обучении без такого образования есть, но это скорее исключение.
Что почитать
«Элементы статистического обучения», Тревор Хасти, Роберт Тибширани и Джером Фридман — если после учебы в университете осталось много пробелов. Классические разделы машинного обучения представлены в терминах математической статистики со строгими математическими вычислениями.
«Глубокое обучение», Ян Гудфеллоу. Лучшая книга о математических принципах, лежащих в основе нейронных сетей.
«Нейронные сети и глубокое обучение», Майкл Нильсен. Для знакомства с основными принципами.
Полное руководство по математике и статистике для Data Science. Крутое и нескучное пошаговое руководство, которое поможет сориентироваться в математике и статистике.
Введение в статистику для Data Science поможет понять центральную предельную теорему. Оно охватывает генеральные совокупности, выборки и их распределение, содержит полезные видеоматериалы.
Полное руководство для начинающих по линейной алгебре для специалистов по анализу данных. Всё, что необходимо знать о линейной алгебре.
Линейная алгебра для Data Scientists. Интересная статья, знакомящая с основами линейной алгебры.
Шаг 2. Программирование
Большим преимуществом будет знакомство с основами программирования. Вы можете немного упростить себе задачу: начните изучать один язык и сосредоточьтесь на всех нюансах его синтаксиса.
При выборе языка обратите внимание на Python. Во-первых, он идеален для новичков, его синтаксис относительно прост. Во-вторых, Python многофункционален и востребован на рынке труда.
Что почитать
«Автоматизация рутинных задач с помощью Python: практическое руководство для начинающих». Практическое руководство для тех, кто учится с нуля. Достаточно прочесть главу «Манипулирование строками» и выполнить практические задания из нее.
Codecademy — здесь вы научитесь хорошему общему синтаксису.
Легкий способ выучить Python 3 — блестящий мануал, в котором объясняются основы.
Dataquest поможет освоить синтаксис.
The Python Tutorial — официальная документация.
После того, как изучите основы Python, познакомьтесь с основными библиотеками:
- Numpy : документация — руководство
- Scipy : документация — руководство
- Pandas : документация — руководство
Визуализация:
- Matplotlib : документация — руководство
- Seaborn : документация — руководство
Машинное обучение и глубокое обучение:
- SciKit-Learn: документация — руководство
- TensorFlow : документация — руководство
- Theano : документация — руководство
- Keras: документация — руководство
Обработка естественного языка:
NLTK — документация — руководство
Web scraping (Работа с web):
BeautifulSoup 4 — документация — руководство
Математика для анализа данных от онлайн-университета «Нетология»
Для кого
Курс для специалистов в области Data Science и аналитиков данных. Его цель — создать крепкий теоретический бэкграунд для более точного прогнозирования, интерпретации данных и выбора инструментов для эффективного решения поставленных задач.
Необходимым требованием является базовый уровень владения Python и знание библиотек NumPy, SciPy, Matplotlib.
Чему научат
Курс включает линейную алгебру, математический анализ и теорию вероятностей
Внимание акцентировано на тех знаниях, которые важны для полноценной работы с данными и применяются специалистами Data Science. Теория дается в связке с практикой: после каждой лекции идет практическое задание
Вас научат использовать различные методы оптимизации для поиска локального минимума функции, применять закон больших чисел для оценки математического ожидания и находить оптимальное решение для разных критериев, необходимое для корректной настройки модели алгоритмов. Для закрепления знаний на практике в финале курса вам необходимо будет выполнить итоговую работу: провести визуальный анализ данных и решить практическую задачу с использованием методов оптимизации функций.
Особенности
Курс проходит в форме видеолекций: 2 лекции по 1,5 часа в неделю. Посмотреть видео можно в личном кабинете в любое удобное время. Там же доступны практические задания, выполнение которых проверяет и комментирует преподаватель. В течение всего курса работает обратная связь: преподаватели отвечают на любые вопросы.
По окончанию программы выдается удостоверение о повышении квалификации. Выпускникам обещают поддержку Центра развития карьеры «Нетологии».
Data Scientist: кто это и что он делает
В переводе с английского Data Scientist – это специалист по данным. Он работает с Big Data или большими массивами данных.
Источники этих сведений зависят от сферы деятельности. Например, в промышленности ими могут быть датчики или измерительные приборы, которые показывают температуру, давление и т. д. В интернет-среде – запросы пользователей, время, проведенное на определенном сайте, количество кликов на иконку с товаром и т. п.
Данные могут быть любыми: как текстовыми документами и таблицами, так и аудио и видеороликами.
От области деятельности зависят и результаты работы Data Scientist. После извлечения нужной информации специалист устанавливает закономерности, подвергает их анализу, делает прогнозы и принимает бизнес-решения.
Человек этой профессии выполняет следующие задачи: оценивает эффективность и работоспособность предприятия, предлагает стратегию и инструменты для улучшения, показывает пути для развития, автоматизирует нудные задачи, помогает сэкономить на расходах и увеличить доход.
Его труд заканчивается созданием модели кода программы, сформировавшейся на основе работы с данными, которая предсказывает самый вероятный результат.
Профессия появилась относительно недавно. Лишь десятилетие назад она была официально зафиксирована. Но уже за такой короткий промежуток времени стала актуальной и очень перспективной.
Каждый год количество информации и данных увеличивается с геометрической прогрессией. В связи с этим информационные массивы уже не получается обрабатывать старыми стандартными средствами статистики. К тому же сведения быстро обновляются и собираются в неоднородном виде, что затрудняет их обработку и анализ.
Вот тут на сцене и появляется Data Scientist. Он является междисциплинарным специалистом, у которого есть знания статистики, системного и бизнес-анализа, математики, экономики и компьютерных систем.
Знать все на уровне профессора не обязательно, а достаточно лишь немного понимать суть этих дисциплин. К тому же в крупных компаниях работают группы таких специалистов, каждый из которых лучше других разбирается в своей области.
Эти знания помогают ему выполнять свои должностные обязанности:
- взаимодействовать с заказчиком: выяснять, что ему нужно, подбирать для него подходящий вариант решения проблемы;
- собирать, обрабатывать, анализировать, изучать, видоизменять Big Data;
- анализировать поведение потребителей;
- составлять отчеты и делать презентации по выполненной работе;
- решать бизнес-задачи и увеличивать прибыль за счет использования данных;
- работать с популярными языками программирования;
- моделировать клиентскую базу;
- заниматься персонализацией продуктов;
- анализировать эффективность деятельности внутренних процессов компании;
- выявлять и предотвращать риски;
- работать со статистическими данными;
- заниматься аналитикой и методами интеллектуального анализа;
- выявлять закономерности, которые помогают организации достигнуть конечной цели;
- программировать и тренировать модели машинного обучения;
внедрять разработанную модель в производство.
Четких границ требований к Data Scientist нет, поэтому работодатели часто ищут сказочное создание, которое может все и на превосходном уровне. Да, есть люди, которые отлично понимают статистику, математику, аналитику, машинное обучение, экономику, программирование. Но таких специалистов крайне мало.
Еще часто Data Scientist путают с аналитиком. Но их задачи несколько разные. Поясню, что такое аналитика и как она отличается от деятельности Data Scientist, на примере и простыми словами.
В банк пришел клиент, чтобы оформить кредит. Программа начинает обрабатывать данные этого человека, выясняет его кредитную историю и анализирует платежеспособность заемщика. А алгоритм, который решает выдавать кредит или нет, – продукт работы Data Scientist.
Аналитик же, который работает в этом банке, не интересуется отдельными клиентами и не создает технические коды и программы. Вместо этого он собирает и изучает сведения обо всех кредитах, что выдал банк за определенный период, например, квартал. И на основе этой статистики решает, увеличить ли объемы выдачи кредитов или, наоборот, сократить.
Аналитик предлагает действия для решения задачи, а Data Scientist создает инструменты.
Как стать Data Scientist с нуля?
Давайте разберемся, с чего начать обучение профессии, и как можно стать специалистом по анализу данных.
- Первый способ – поступить в профильный вуз и параллельно освоить необходимые языки программирования и инструменты визуализации. Есть несколько вузов, выпускники которых особенно ценятся среди работодателей.
- Второй способ – пойти на курсы, где вы изучите математическую базу и получите практические навыки. Если у вас уже есть техническое образование, пусть даже не связанное с Data Scientist, это оптимальный вариант. Если технического образования нет, то найти первую работу будет сложнее. Вам могут помочь курсы, где есть программы помощи с трудоустройством.
-
Часто в профессию переходят аналитики данных и Python-разработчики. Сфера активно растет, поэтому людей привлекают высокие зарплаты и перспективы.
Также освоить профессию Data Scientist можно через интернет. Многие люди, которые ищут, с чего начать карьеру в этой сфере, выбирают данный путь. Есть несколько онлайн-университетов, где можно пройти обучение:
|
Название курса и ссылка на него |
Описание |
|
Профессия Data Scientist в Skillbox |
Курс в университете Skillbox. Подходит новичкам и людям без опыта работы в IT. Вы изучите теорию (анализ данных, Machine Learning, статистика, теория вероятностей, функции, работа с производными и многое другое), научитесь программировать на Python и языке R, изучите библиотеки Pandas, NumPy и Matplotlib, работу с базами данных. Сможете создавать рекомендательные системы, применять нейронные сети для решения задач, визуализировать данные. Включает практические задания. На защите диплома присутствуют работодатели. |
|
Обучение Data Scientist в Нетологии (уровень – с нуля) |
Курс походит людям, которые хотят сменить текущую профессию на Data Scientist. Включает программу помощи с трудоустройством. Изучают математику для анализа данных, построение моделей, управление data-проектами, Python, базы данных, обработку естественного языка (NLP) и многое другое. Объема полученных знаний хватит для старта в карьере. Преподаватели – сотрудники крупных ИТ и финансовых компаний. |
В интернете есть бесплатные курсы по Data Scientist. Если вы думаете, подойдет или нет вам эта профессия, то можете посмотреть данные уроки и получить более полное представление и описание данной работы:
- Анализ данных на Python в задачах и примерах
- Курс по библиотеке Pandas
- Курс по машинному обучению для новичков
- Бесплатный курс по базам данных MySQL
-
Работа с Google Таблицами для начинающих
Уровень 1. От стажёра к джуну
Главное на этом уровне — научиться работать с датасетами в виде CSV-файлов, обрабатывать и визуализировать данные, понимать, что такое линейная регрессия.
Основы обработки данных
В первую очередь придётся манипулировать данными, чистить, структурировать и приводить их к единой размерности или шкале. От новичка ждут уверенной работы с библиотеками Pandas и NumPy и некоторых специальных навыков:
- импорт и экспорт данных в CSV-формате;
- очистка, предварительная подготовка, систематизация данных для анализа или построения модели;
- работа с пропущенными значениями в датасете;
- понимание принципов замены недостающих данных (импутации) и их реализация — например, замена средними или медианами;
- работа с категориальными признаками;
- разделение датасета на обучающую и тестовую части;
- нормировка данных с помощью нормализации и стандартизации;
- уменьшение объёма данных с помощью техник снижения размерности — например, метода главных компонент.
Визуализация данных
Новичок должен знать основные принципы хорошей визуализации и инструменты — в том числе Python-библиотеки matplotlib и seaborn (для R — ggplot2).
Какие компоненты нужны для правильной визуализации данных:
Данные. Прежде чем решить, как именно визуализировать данные, надо понять, к какому типу они относятся: категориальные, численные, дискретные, непрерывные, временной ряд.
Геометрия. То есть какой график вам подойдёт: диаграмма рассеяния, столбиковая диаграмма, линейный график, гистограмма, диаграмма плотности, «ящик с усами», тепловая карта.
Координаты. Нужно определить, какая из переменных будет отражена на оси x, а какая — на оси y
Это важно, особенно если у вас многомерный датасет с несколькими признаками.
Шкала. Решите, какую шкалу будете использовать: линейную, логарифмическую или другие.
Текст
Всё, что касается подписей, надписей, легенд, размера шрифта и так далее.
Этика. Убедитесь, что ваша визуализация излагает данные правдиво. Иными словами, что вы не вводите в заблуждение свою аудиторию, когда очищаете, обобщаете, преобразовываете и визуализируете данные.
Обучение с учителем: предсказание непрерывных переменных
Главное: стажёру придётся изучить методы регрессии, стать почти на ты с библиотеками scikit-learn и caret, чтобы строить модели линейной регрессии
Но чтобы стать полноценным джуниором, стажёр должен знать и уметь ещё кучу всего (осторожно — там сложные слова, но есть подсказки):
- проводить простой регрессионный анализ с помощью NumPy или Pylab;
- использовать библиотеку scikit-learn, чтобы решать задачи с множественной регрессией;
- понимать методы регуляризации: метод LASSO, метод упругой сети, метод регуляризации Тихонова;
- знать непараметрические методы регрессии: метод k-ближайших соседей и метод опорных векторов;
- понимать метрики оценок моделей регрессии: среднеквадратичная ошибка, средняя абсолютная ошибка и коэффициент детерминации R-квадрат;
- сравнивать разные модели регрессии.
Как различаются роли дата-инженеров и дата-сайентистов
Инженер данных — это специалист, который, с одной стороны, разрабатывает, тестирует и поддерживает инфраструктуру работы с данными: базы данных, хранилища и системы массовой обработки. С другой стороны, дата-инженер очищает и «причёсывает» данные для использования аналитиками и дата-сайентистами, то есть создаёт конвейеры обработки данных.
Дата-сайентист создаёт и обучает предиктивные (и не только) модели с помощью алгоритмов машинного обучения и нейросетей, помогая бизнесу находить скрытые закономерности, прогнозировать развитие событий и оптимизировать ключевые бизнес-процессы.
Главное различие между Data Scientist и Data Engineer состоит в том, что обычно у них разные цели. Оба работают для того, чтобы данные были доступными и качественными. Если дата-сайентист находит ответы на свои вопросы и проверяет гипотезы в экосистеме данных (например, на базе Hadoop), то дата-инженер создаёт пайплайн обслуживания алгоритма машинного обучения, написанного дата-сайентистом, в кластере Spark внутри той же экосистемы.
Инженер данных приносит ценность бизнесу, работая в команде. Он выступает важным звеном между различными участниками: от разработчиков до бизнес-потребителей отчетности. Также помогает повысить продуктивность аналитиков — от маркетинговых и продуктовых до BI.
Дата-сайентист принимает активное участие в стратегии компании и извлечении инсайтов, принятии решений, внедрении алгоритмов автоматизации, моделирования и генерации ценности из данных.
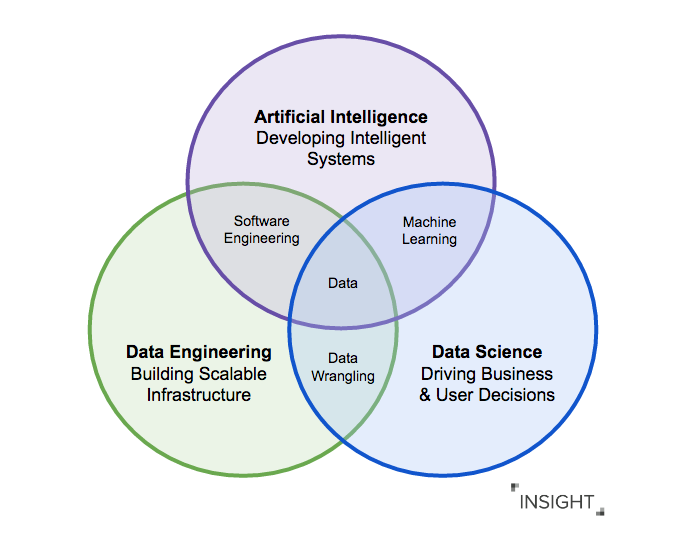
Работа с данными подчиняется принципу GIGO (garbage in — garbage out): если аналитики и дата-сайентисты имеют дело с неподготовленными и потенциально некорректными данными, то результаты даже с помощью самых изощрённых алгоритмов анализа будут неверны.
Инженеры данных решают эту проблему, выстраивая пайплайны по обработке, очистке и трансформации данных и позволяя дата-сайентисту работать уже с качественными данными.
На рынке много инструментов для работы с данными на каждом этапе: от их появления до вывода на дашборд для совета директоров
И важно, чтобы решение об их использовании принималось дата-инженером, — не потому, что это модно, а потому что он действительно поможет в работе остальным участникам процесса
Условно: если компании нужно подружить BI и ETL — загрузку данных и обновления отчётов, вот типичный legacy-фундамент, с которым придётся иметь дело Data Engineer (хорошо, если в команде кроме него будет ещё и архитектор).
Обязанности Data Engineer
- Разработка, построение и обслуживание инфраструктуры работы с данными.
- Обработка ошибок и создание надёжных конвейеров обработки данных.
- Приведение неструктурированных данных из различных динамических источников к виду, необходимому для работы аналитиков.
- Предоставление рекомендаций по повышению консистентности и качества данных.
- Обеспечение и поддержка архитектуры данных, используемой дата- сайентистами и аналитиками данных.
- Обработка и хранение данных последовательно и эффективно в распределённом кластере на десятки или сотни серверов.
- Оценка технических компромиссов инструментов для создания простых, но надёжных архитектур, которые смогут пережить сбои.
- Контроль и поддержка потоков данных и связанных систем (настройка мониторинга и алертов).
Теория
По ходу изучения технических моментов вам неизбежно будет встречаться теория, которая стоит за кодом.
Например, я изучаю код, чтобы научиться применять какую-то технику (скажем, метод k-средних, KMeans), а когда она сработает, начинаю глубже разбираться с понятиями, которые с ней связаны (например, с инертностью, Inertia).
- Все сопутствующие алгоритмам математические термины есть в той же .
- Ниже я перечислю главное, что нужно изучить из теории вместе с прикладными аспектами. Почти по всем этим вещам есть бесплатные уроки на khan academy. Во время регистрации или в профиле можно выбрать нужные вам дисциплины, и сайт выдаст пошаговый план по каждому предмету.
Математика
Математический анализ (Calculus)
В этом разделе математики рассматривается связь между функцией и её производной, из-за которой изменение одной переменной величины приводит к изменению другой. Матанализ позволяет, например, выявлять паттерны, понимать, как функция меняется с течением времени.
В машинном обучении матанализ помогает оптимизировать производительность алгоритмов. Один из примеров — метод градиентного спуска. Он состоит в том, что при обучении по одному изменяют весовые коэффициенты нейросети для поиска минимального значения функции потерь.
Что нужно знать.
Производные (Derivatives)
- Геометрический смысл (Geometric definition)
- Вычисление производной функции (Calculating the derivative of a function)
- Нелинейные функции (Nonlinear functions)
Цепное правило (или Правило дифференцирования сложной функции, Chain rule)
- Сложные функции (Composite functions)
- Производные сложных функций (Composite function derivatives)
- Множественные функции (Multiple functions)
Градиенты (Gradients)
- Частные производные (Partial derivatives)
- Производные по направлению (Directional derivatives)
- Интегралы (Integrals)
Линейную алгебру (Linear Algebra)
Многие распространённые инструменты машинного обучения, в том числе XGBOOST, для хранения входных данных и обработки данных используют матрицы. Матрицы, наряду с векторными пространствами и линейными уравнениями, изучает линейная алгебра
Уверенное знание этого раздела математики очень важно для понимания механизма многих методов машинного обучения
Что нужно знать
Векторы и пространства (Vectors and spaces)
- Векторы (Vectors)
- Линейные комбинации (Linear combinations)
- Линейная зависимость и независимость (Linear dependence and independence)
- Скалярное произведение и векторное произведение (Vector dot and cross products)
Матричные преобразования (Matrix transformations)
- Функции и линейные преобразования (Functions and linear transformations)
- Умножение матриц (Matrix multiplication)
- Обратные функции (Inverse functions)
- Транспонирование матрицы (Transpose of a matrix)
Статистика для Data Scientist
Что нужно знать
Описательная/дескриптивная статистика (Descriptive/Summary statistics)
- Описание выборки данных (How to summarise a sample of data)
- Типы распределений (Different types of distributions)
- Асимметрия, эксцесс, меры центральной тенденции, например среднее арифметическое, медиана, мода (Skewness, kurtosis, central tendency, e.g. mean, median, mode)
- Меры зависимости и взаимосвязь переменных величин, например корреляция и ковариация (Measures of dependence, and relationships between variables such as correlation and covariance)
Планирование эксперимента (Experiment design)
- Проверка гипотез (Hypothesis testing)
- Семплирование (Sampling)
- Тесты на статистическую значимость (Significance tests)
- Случайность (Randomness)
- Вероятность (Probability)
- Доверительные интервалы и статистический вывод по двум выборкам (Confidence intervals and two-sample inference)

11 курсов по Data Science для новичков и профессионалов
По теме
11 курсов по Data Science для новичков и профессионалов
Машинное обучение (Machine learning)
- Вывод о наклоне линии регрессии (Inference about slope)
- Линейная и нелинейная регрессия (Linear and non-linear regression)
- Классификация (Classification)
Уровень 2. От джуна к мидлу
Прочно закрепив на практике все те неприличные слова из блока для джуна, можно штурмовать более продвинутые техники и методы: предсказание дискретных переменных в обучении с учителем (supervised learning), оценку и настройку моделей, а также сбор разных алгоритмов в единые ансамбли методов. Вы уже поняли, что сейчас опять начнётся ковровое бомбометание дата-сайентистскими терминами? Не вздумайте употреблять их в публичных местах — а то бабушки начнут креститься, как будто увидели сатаниста или парня с татуировками по всему телу 🙂
Обучение с учителем: предсказание дискретных переменных
Начните с алгоритмов бинарной классификации — вот какие надо знать мидлу:
- перцептрон;
- логистическая регрессия;
- метод опорных векторов;
- решающие деревья и случайный лес;
- k-ближайших соседей;
- наивный байесовский классификатор.
Дополнительно: небольшая статья о том, как создать простую модель машинного обучения. Формируем и делим датасет, обучаем модель Random Forest, предсказываем дискретную переменную и вот это всё.
Мастхэв — на хорошем уровне работать с библиотекой scikit-learn (она уже тут мелькала), которая помогает строить модели. Также придётся решать задачи на нелинейную классификацию с помощью метода опорных векторов, освоить несколько метрик для оценки алгоритмов классификации — точность, погрешность, чувствительность, матрица ошибок, F-мера, ROC-кривая.
Оценка моделей и оптимизация гиперпараметров
Чтобы правильно оценивать и настраивать модели, специалисту нужно:
- соединять трансформеры (к Оптимусу Прайму и Бамблби они отношения не имеют — пока) и модули оценки (estimators) в конвейеры машинного обучения (machine learning pipelines).
- использовать кросс-валидацию для оценки модели;
- устранять ошибки в алгоритмах классификации с помощью кривых обучения и валидации;
- выявлять проблемы смещения и дисперсии с помощью кривых обучения;
- работать с переобучением и недообучением, используя кривые валидации;
- настраивать модель машинного обучения и оптимизировать гиперпараметры с помощью поиска по решётке;
- читать и правильно интерпретировать матрицу ошибок;
- строить и правильно толковать ROC-кривую.
Сочетание разных моделей в ансамбле методов
- использовать ансамбль методов с различными классификаторами;
- комбинировать разные алгоритмы классификации;
- знать, как оценить и настроить ансамбль моделей классификации.
Дата-сайентисты в облаках
Облегчить и ускорить работу по сбору данных, построению и развертыванию моделей помогают специальные облачные платформы. Именно облачные платформы для машинного обучения стали самым актуальным трендом в Data Science. Поскольку речь идет о больших объемах информации, сложных ML-моделях, о готовых и доступных для работы распределенных команд инструментах, то дата-сайентистами понадобились гибкие, масштабируемые и доступные ресурсы.
Именно для дата-сайентистов облачные провайдеры создали платформы, ориентированные на подготовку и запуск моделей машинного обучения и дальнейшую работу с ними. Пока таких решений немного и одно из них было полностью создано в России. В конце 2020 года компания Sbercloud представила облачную платформу полного цикла разработки и реализации AI-сервисов — ML Space. Платформа содержит набор инструментов и ресурсов для создания, обучения и развертывания моделей машинного обучения — от быстрого подключения к источникам данных до автоматического развертывания обученных моделей на динамически масштабируемых облачных ресурсах SberCloud.

Футурология
«Я бы вакцинировал троих на миллион». Интервью с нейросетью GPT-3
Сейчас ML Space — единственный в мире облачный сервис, позволяющий организовать распределенное обучение на 1000+ GPU. Эту возможность обеспечивает собственный облачный суперкомпьютер SberCloud — «Кристофари». Запущенный в 2019 году «Кристофари» является сейчас самым мощным российским вычислительным кластером и занимает 40 место в мировом рейтинге cуперкомпьютеров TOP500
Платформу уже используют команды разработчиков экосистемы Сбера. Именно с ее помощью было запущено семейство виртуальных ассистентов «Салют». Для их создания с помощью «Кристофари» и ML Space было обучено более 70 различных ASR- моделей (автоматическое распознавание речи) и большое количество моделей Text-to-Speech. Сейчас ML Space доступна для любых коммерческих пользователи, учебных и научных организаций.
«ML Space – это настоящий технологический прорыв в области работы с искусственным интеллектом. По нескольким ключевым параметрам ML Space уже превосходит лучшие мировые решения. Я считаю, что сегодня ML Space одна из лучших в мире облачных платформ для машинного обучения. Опытным дата-сайентистам она предоставляет новые удобные инструменты, возможность распределенной работы, автоматизации создания, обучения и внедрения ИИ-моделей. Компаниям и организациям, не имеющим глубокой ML-экспертизы, ML Space дает возможность впервые использовать искусственный интеллект в своих продуктах, приложениях и рабочих процессах», — уверен Отари Меликишвили, лидер продуктового вправления AI Cloud, компании SberCloud.
Облака помогают рынку все шире использовать платформы для работы с данными, предлагая безграничные вычислительные мощности, подтверждают аналитики Mordor Intelligence.
По мнению экспертов из Anaconda, потребуется время, чтобы бизнес и сами специалисты созрели для широкого использования инструментов DS и смогли получить результаты. Но прогресс уже очевиден. «Мы ожидаем, что в ближайшие два-три года Data Science продолжит двигаться к тому, чтобы стать стратегической функцией бизнеса во многих отраслях», — прогнозирует компания.
Как выглядит его рабочий день?
Нужно ли дата-сайентисту работать в офисе, зависит от компании. На hh.ru можно найти около 10% вакансий удаленной работы. Иногда компании предлагают комбинировать работу из офиса и из дома. Взаимодействие с командой зависит от масштаба задач: новичок, готовящий данные к обработке, может общаться только с руководителем, а синьор дата-сайентист должен общаться с заказчиками и делегировать задачи команде.
Как правило, рабочий день начинается с разбора почты и общения с командой. Затем начинается работа с данными: нужно писать SQL-запросы и готовить массивы информации к машинному обучению, писать код модели на Python и прогонять данные через модель. В процессе работы нужно периодически созваниваться с командой и менеджерами, которые будут использовать модель на практике.
В каких случаях становятся специалистом по Data Science?
- Когда нравится анализ и систематизация данных и есть интерес к передовым технологиям — дата-сайентисты работают с искусственным интеллектом, нейросетями и большими данными.
- Когда хочется заниматься исследованиями и наукой на качественно новом уровне.
- Когда есть опыт в обычной разработке и есть желание освоить больший набор инструментов и заниматься масштабными проектами.
- Когда на текущей работе мало перспектив, хочется освоить перспективное направление и больше зарабатывать.
Глеб Синяков
аналитик-разработчик в «Тинькофф»
Всех, кто приходит в Data Science, можно разделить на четыре потока. Есть те, кто становятся дата-сайентистами после профессионального образования, но в университетах таких курсов пока немного. Также есть люди технических и научных профессий, которые хотят найти более перспективную работу с большой зарплатой. Третий поток — разработчики, которые устают от скучного программирования и ищут интересные задачи. Есть специалисты, которые начинали с нуля: если у новичков есть самодисциплина и интерес к большим данным, то они становятся хорошими дата-сайентистами. Наконец, есть те, к кому Data Science приходит сам, например к биоинформатикам.
Подробнее о том, чем занимается Глеб Синяков, читайте в рассказе о его профессии.
Как он это делает?
Задачи аналитику ставит владелец продукта или проектный менеджер. Например, разработать и внедрить какую-то модель на производстве. Владелец продукта оценивает сложность задачи и собирает необходимую для решения команду: дата-сайентист, фронтенд- и бэкенд-разработчики, дизайнер и так далее. Специалистов каждой специальности может быть несколько, а может и ни одного, в зависимости от задачи и предполагаемого решения.
Расскажу, как мы в СИБУРе строим модель. Допустим, мы хотим предсказать факт брака детали по данным с датчиков на производстве.

- Первый этап — сбор данных. Аналитик готовит данные для анализа: выгружает из различных источников, обрабатывает пропуски в данных (значения, которые должны быть, но отсутствуют). На выходе получается таблица.
- Второй этап — предварительный анализ. Бывает полезно нарисовать разные графики и внимательно их изучить. В шутку некоторые аналитики называют это методом «пристального взгляда». Это может дать интересные соображения, помочь выявить странности и много чего еще, что поможет в решении задачи.
- Третий этап — построение признакового описания. Поясню, что это. У нас уже есть таблица с данными от датчиков, но в большинстве случаев этого мало. Необходимо самостоятельно рассчитать некоторые величины, которые могут помочь классифицировать деталь как бракованную.
Например, может быть недостаточно измерить температуру в разных точках детали датчиками. Есть смысл рассчитать среднее арифметическое по всем этим датчикам, а также максимальную, минимальную температуру, разброс температур и много чего еще.
Таким образом, рассчитывая и добавляя новые величины, мы расширяем признаковое описание нашей детали. Именно это описание (набор чисел для каждой детали) мы используем для построения модели. В нашем примере моделью будет являться некоторый алгоритм, который пытается восстановить зависимость между признаковым описанием детали и ответом (есть брак или нет).
В итоге модель обычно представляет из себя код, который может прочитать данные (например, из таблицы Excel или из базы данных), построить предсказания и записать результат (опять-таки в таблицу или базу данных).
Но в таком виде модель еще нельзя считать законченной. Модель должна быть внедрена и работать у заказчика.

Если говорить о конкретных проектах, в которых я принимал участие в СИБУРе, то первой была задача разработки модели для производства изобутилена, которая должна была предсказывать коксование. На решетках реактора образуются углеродные отложения, которые могут решетки повредить.
Помимо самой модели, необходимо было сделать визуализацию предсказаний, которая должна обновляться в реальном времени после каждого пересчета предсказаний, а также реализовать регулярную загрузку актуальных данных в базу для расчета предсказаний. Этой задачей я занимался один, при этом периодически пользовался помощью коллег в некоторых вопросах, связанных с производственной системой хранения данных.
В этом проекте я выступаю уже больше как архитектор и разработчик фреймворка, отвечающего за все вычисления. В то время как мой коллега, тоже аналитик данных, но с профильным химическим образованием, больше решает задачи моделирования, в том числе с использованием химии и физики, хотя это разделение обязанностей весьма условно. Также в этом проекте участвуют фронтенд-разработчики, так как визуальная часть нашего решения достаточно сложна.