Еще не зарегистрированы?
Содержание:
- Как найти популярные темы Яндекса, через рейтинг сайтов Liveinternet
- Определение частотности запросов по видам
- Дополнительные возможности
- Программы парсеры
- Что такое частотность запросов
- Как проверить частоту запросов в Яндексе
- Как правильно пользоваться Вордстатом
- Сбор частот
- Сезонность в Яндекс Вордстат — история поисковых фраз
- Инструменты для упрощения работы с «Вордстатом» – расширения и программы
- Высоко- средне- и низкочастотные запросы
- Дополнительные операторы
- Виды частотностей в поисковой системе Яндекс
Как найти популярные темы Яндекса, через рейтинг сайтов Liveinternet
Понятное дело, что большая часть счетчиков будет закрыта паролем, но если поискать, то можно найти сайты с открытыми данными. Особенно ценная информация, когда Вы видите большую часть переходов из поисковых систем – Яндекса и Гугл, на сайт. И при этом, если даже статистика “по поисковым фразам” скрыта, иногда бывает открыта статистика по “точкам входа”. А зная эти данные, можно видеть трафиковые статьи на сайте, и несложно догадаться что эта тема популярная, и при дальнейшем её анализе, можно увидеть самые популярные ключевые слова, по которым находят статью в поиске.
Попробуйте поискать, сайты с некоторыми открытыми данными по статистике, по общей ссылке рейтинга: https://www.liveinternet.ru/rating/ru/

Выбираем рубрику, и открываем статистику десятков сайтов. Большая часть, будет закрыта паролем, но посмотрите ещё и 100% найдете сайты у которых часть данных открыта. Вот пример:
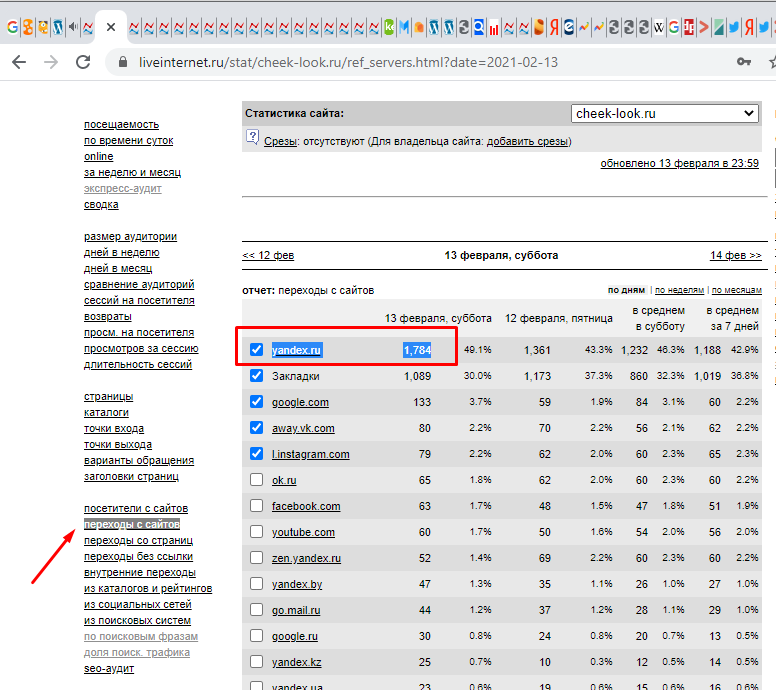
Первым делом, нам нужно убедиться, что трафик на сайте поисковый. Потому как, если много посетителей из социальных сетей или других источников, а поисковая система Яндекса, не дает трафик, то точки входа не будут иметь органического трафика. И эти данные, не будут такими ценными в поиске популярных тем. А когда трафик из Яндекса есть, и он в приятных цифрах, то можно перейти в следующий раздел, под названием “точки входа” (если доступно):
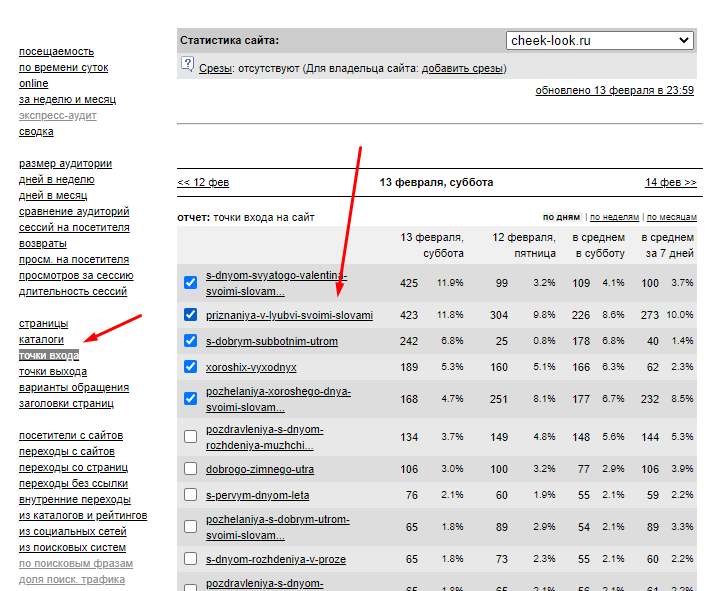
Отлично! Вижу статьи с трафиком, прикидываю примерное кол-во посетителей в эти статьи из поиска. И можно сделать подобные статьи, только ещё лучше и полезней. Поисковые фразы можно будет найти в самой поисковой строке. Вы уже умеете это делать, если дошли до этого момента. А вот и пациент, и одна из фраз, по которой находят этот сайт.

Другой пример, сайт про комнатные растения, с хорошим трафиком из Яндекса:

70% трафика из Яндекса, но “по поисковым фразам” закрыта статистика:


Если Вам понравился этот способ, напишите комментарий ниже…
Определение частотности запросов по видам
Высокочастотные (ВЧ)
Они имеют широкую направленность и содержат, как правило, одно или несколько слов, наиболее популярных среди пользователей при поиске той или иной информации. Высокочастотные запросы применяются в качестве рекламы по формированию положительного мнения целевой аудитории о компании в целом и предлагаемых товарах/услугах в частности.
- ВЧ не подходят для продвижения веб-ресурсов, продолжительность работы которых составляет менее одного года. В этом случае необходимо начинать с НЧ и СЧ.
- Максимальная частотность запросов ВЧ может достигать нескольких десятков тысяч (согласно Статистике запросов).
- Они задаются пользователями, которые только начинают изучение предметной области и, будучи наиболее конкурентным вариантом, стоят в продвижении гораздо дороже других видов.
Низкочастотные (НЧ)
Они имеют узкую направленность, описывают конкретную потребность целевой аудитории и, как правило, состоят из трех и более слов. Другими словами, НЧ задают люди, точно знающие, какой товар в какой комплектации им необходим (например, купить зубную щетку philips в Москве). Средняя частотность запросов здесь может составлять от 1 тысячи просмотров. Низкочастотные запросы наиболее конверсионные и подходят для продвижения любых интернет-сайтов на всех этапах. Основное преимущество НЧ состоит в том, что, не имея большой спрос, они не являются конкурентными и стоят гораздо дешевле для поискового продвижения.
Дополнительные возможности
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки». К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны)
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу . Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
Программы парсеры
Для точной обработки ключевых слов рекомендуется использовать программные комплексы. Преимущество – они работают напрямую с базами данных Ворстат. Полная версия платная, некоторые разработчики предоставляют демо-режим с ограниченным функционалом.
Кей Коллектор
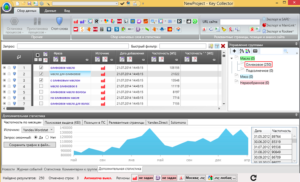
Программа «Кей Коллектор» популярна среди разработчиков и СЕО-оптимизаторов. Причины – работа с популярными поисковыми системами, сегментация выборок по параметрам пользователя. Предоставляется только на платной основе, стоимость зависит от количества приобретаемых лицензий.
Особенности «Кей Коллектор»:
- Анализируется только актуальная статистика, сбор информации ведется напрямую из баз данных (БД) Яндекса.
- Ключевые слова подбираются по региону, частоте, сезонности.
- Учитываются стоп-слова.
Возможен многопоточный режим работы. Но есть вероятность получения бана или многократного ввода капчи при формировании нескольких потоков запроса информации с одного IP. Возможен сбор информации через Яндекс.Директ, что уменьшает скорость обработки.
Словоёб
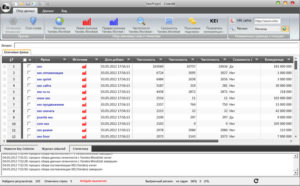
Бесплатная альтернатива Кей Коллектор, но с меньшими функциональными возможностями. Отличие – «Словоёб» работает только с Вордстат. При анализе некоторых ключевых фраз могут не учитываться низкочастотные запросы, которые есть в статистике Яндекс.Директ. Глубина эффективного парсинга ограничена 40 страницами.
Особенности программы «Словоёб»:
- меньшие возможности работы с таблицами;
- нет «поисковых подсказок»;
- отсутствует сбор главных страниц выдачи;
- нет позиций по запросам.
Программа подходит для формирования СЯ небольшого проекта. Причина – скорость обработки полученных данных, нет углубленного анализа запросов.
Магадан
Технические ограничения в бесплатном варианте программы:
- нельзя выбрать региональность для запросов;
- отключены фильтры по количеству символов, слов;
- нет импорта файлов со стоп-словами;
- нельзя задавать правила к генерируемым ключевым фразам;
- отключен экспорт КС.
Несмотря на такие ограничения «Магадан» можно использовать для формирования СЯ 1-3 проектов. Но по отзывам пользователей по сравнению с ручной обработкой Вордстата теряются низкочастотные запросы.
Что такое частотность запросов
Главное с чем нужно разобраться, что такое частотность запросов? Это число запросов на интересующие ключевые фразы, взятое за заданный период. Одни запросы могут задаваться единожды, тогда как другие, задаются по миллиону раз в неделю. Владельцам сайтов, которые хотят расширить аудиторию пользователей, выгоднее применять популярные запросы. В разных поисковых системах используется свой метод определения частотности.
Виды
Существуют следующие виды запросов по частотности:
- высокочастотные;
- среднечастотные;
- низкочастотные.
Определение частотности запросов продемонстрирует, к какой категории относятся используемые ключевые фразы.
Как проверить частоту запросов в Яндексе
У Яндекса есть свой специальный сервис по определению статистики «Подбор слов», находящийся по адресу https://wordstat.yandex.ru. Частотность запросов Яндекс Вордстат показывает за прошедший месяц. Есть три вида частотности:
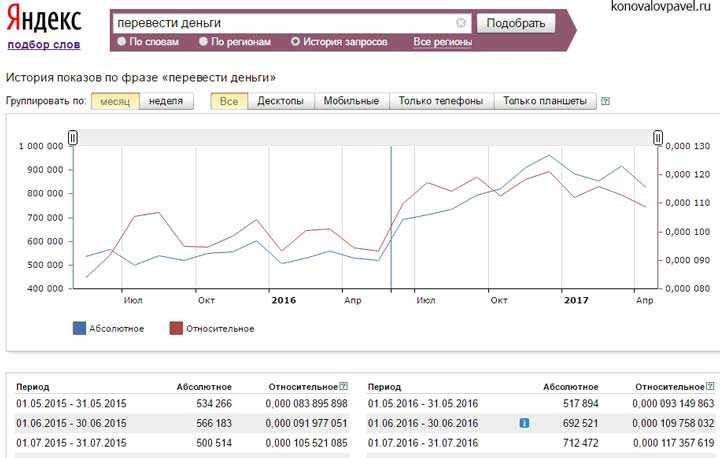
- Базовая частотность. Включает все запросы, содержащие введённые слово или словосочетание. Ввели запрос — перевести деньги. В статистике будут учтены запросы: как перевести деньги, как переводить деньги и так далее (смотри скриншот ниже). Общее число 788858 показов в месяц.
- Частотность по точному написанию запроса. Запрос заключается в оператор кавычки «…» «перевести деньги». В эту частотность входят запросы с возможным изменением падежа, окончания: переводить деньги, перевести деньг. То есть с изменением словоформы. Количество показов — 1873.
- Частотность без изменения словоформ. Поисковый запрос заключается в кавычки и перед каждым словом ставится оператор восклицательный знак ! «!перевести !деньги». 1599 показов. Наиболее точная частота показов.
В Яндекс Вордстате есть возможность посмотреть частоту запросов в зависимости от типа устройства пользователя: компьютер, планшет, телефон или вне зависимости (в примере показаны запросы Все).
Также узнать частоту запросов в конкретном регионе. Вкладка История запросов покажет график изменения частотности во времени.
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис, вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:
После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:
Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
Давайте теперь смотреть остальные функции интерфейса:
В блоке 1 — переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.В блоке 2 — очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.В блоке 3 — дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.В блоке 4 — выбираем регион/регионы.
По регионам
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:
А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:
История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:
Но самое профессиональное начинается, когда вы работаете с операторами.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».
С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.
С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.
А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
Вспомогательные операторы
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:
Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».
Круглые скобки «()» — группирует использование нескольких операторов.
Квадратные скобки «[]» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:
Как видим, с неправильным порядком фразу почти никто не вводит:
Сбор частот
Сбор частот позволяет оценить популярность запросов.

Сервис выдает кол-во показов запроса за последние 30 дней.
Статистика обновляется не ежедневно, поэтому не воспринимайте этот период буквально.

Сервис поддерживает различные операторы поиска, поэтому программа способна получать несколько видов частот.
Программа автоматически добавляет нужные операторы при сборе того или иного вида частот (добавлять операторы вручную к текст запросов не требуется).
Базовая частота
Базовая частота соответствует широкому типу вхождения слов. Для выполнения запроса достаточно отправить сам запрос в исходном виде:
- свежий хлеб
- условная вероятность
- теорема Байеса
В результатах могут быть учтены и другие фразы, косвенно относящиеся к запросу «свежий хлеб» в широком соответствии: купить свежий хлеб, свежий ржаной хлеб, рецепт хлеба, свежая выпечка и др.
Фразовая частота
Фразовая частота фиксирует состав слов в искомом запросе, и показы считаются для словосочетания целиком. Для выполнения запроса необходимо добавить двойные кавычки:
- «свежий хлеб»
- «теорема Байеса»
- «плотность распределения»
В результатах к запросу «свежий хлеб» будут учтены только фразы с тем же набором слов:: свежий хлеб, хлеба свежего и др.
Точная фразовая частота
Точная фразовая частота фиксирует не только состав, но и словоформы слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе и взять его в двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе: свежий хлеб, хлеб свежий (порядок не фиксируется).
Точная фразовая частота с порядком
Точная фразовая с порядком частота фиксирует состав, словоформы и порядок следования слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе, взять его в и двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе и том же порядке следования: свежий хлеб.
Частота по маске
Вы можете самостоятельно определить маску запроса, используя поддерживаемые сервисом операторы.
Маска запроса должна содержать фрагмент QUERY, который при сборе частот будет заменяться на текст исследуемого запроса.
Сезонность в Яндекс Вордстат — история поисковых фраз
Интересный раздел, позволяющий познакомиться с динамикой частности выбранной ключевой фразы.
Анализируя данные за несколько лет, вы можете выделить определенную закономерность и понять — существует ли сезонный фактор на интересующий вас товар (или услугу, либо иное явление).
Например, вот история для фразы “москва экскурсии”:
Можно сгруппировать данные по месяцам / неделям, либо — по типу устройства:
История показов по фразе «экскурсии москва». График содержит относительное и абсолютное значение. Можно включить / выключить только абсолютное или только относительное значение. Сам график показов интерактивный:
Здесь же, подробная статистика по датам:
Вы можете смотреть цифры в абсолютных значениях (самый точный вариант):
…либо — относительных (в таком случае, учитывается суммарный показ фразы на странице результатов поиска):
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:
Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/
Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:
Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».
Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:
Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:
Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:
Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:
И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:
Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Высоко- средне- и низкочастотные запросы
Существует еще одна важная классификация, на которую точно стоит обратить внимание при составлении семантического ядра. Согласно ей запросы подразделяются на следующие виды:
- высокочастотные или ВЧ (частотность от 5 000)
- среднечастотные или СЧ (частотность от 1 000 до 5 000)
- низкочастотные запросы или НЧ (частотность от 1 до 1 000)
Цифры очень условные и мы – рекомендуем ориентироваться на нишу и географию продвигаемого сайта. Ниже приводим несколько характеристик, которые способны помочь в классификации запросов.
Высокочастотные запросы
Данный вид запросов включает в себя максимально общие фразы. Они состоят, как правило, из 1-2 слов. По такому ключевику не всегда очевидно, что хочет пользователь, из-за этого они часто имеют более низкую конверсионность. Но всегда есть исключения, поэтому рекомендуем анализировать именно конкретную ситуацию. Если сайт молодой лучше начинать с НЧ и СЧ запросов, а ВЧ подключать со временем.
Пример ВЧ запроса показан ниже:
Среднечастотные запросы
Эти запросы содержат более точные фразы, обычно состоят из 3-4 слов. Хотя они все еще и охватывают большое количество пользователей, но имеют уже более понятный интент. Пример указан ниже на рисунке.
Низкочастотные запросы
Это наиболее точные запросы, показывающие намерения пользователя. Как правило, содержат 5 и более слов. Мы советуем всегда добавлять в СЯ часть НЧ фраз, которые привлекут целевой трафик на сайт. При этом они помогают более эффективно продвигать страницы за счет текстовой оптимизации.
Пример НЗ запроса показан ниже:
Дополнительные операторы
В Yandex WordStat есть еще 5 дополнительных операторов, которые открывают еще больше возможностей по поиску ключевых слов.
1. Квадратные скобки []
Если напишем внутри скобок при запросе конкретное словосочетание, то оно останется в таком порядке, как мы его прописали.
2. Оператор плюс +
Помогает отыскать поисковые запросы, где есть символы, например, предлоги и так далее.
3. Оператор «или»
Используется символом | и применяется для оперативного подбора семантики на веб-страницу, а также для сравнения или смещения некоторых фраз.
4. Оператор группировка ().
Внутри этого оператора прописываются вышеперечисленные символы, чтобы использовать их вместе.
5. Оператор минус.
Обозначается символом — он убирает запросы, которые содержат ненужные слова при изучении статистики слова.
Примеры операторов
1. Квадратные скобки, они фиксируют порядок слов.
2. Оператор +
При этом запросе отражаются все слова купить с прелогом «в» Зтот оператор зафиксировал все слова с предлогом в»
Оператор мнус —
3. Группировка
Мы рассматривали только все плюсы операторов Вордстат, а теперь давайте посмотрим есть ли у них недостатки.
Виды частотностей в поисковой системе Яндекс
Один из инструментов определения частотностей является сервис от поисковой системы (далее ПС) Яндекс – WordStat. Он показывает популярность фразы в одноименной поисковой системе. Причем, посмотреть можно несколько видов частотностей, в зависимости от операторов, которые применяются. На примере запроса «поисковое продвижение» разберемся подробнее.
Поисковое продвижение – такой запрос без каких-либо операторов покажет общую частотность по фразе, ее аналогам и словоформам.
Число 23 504 на рисунке выше означает, какое количество показов было со словом «поисковое продвижение» в ПС Яндекс за последний месяц. Нужно учитывать, что в эту цифру входят и более длинные фразы, например, «поисковое продвижение сайтов» и фразы с измененными словоформами, например, «услуги поискового продвижения».
Оператор «кавычки» («поисковое продвижение») фиксирует количество слов в запросе, а значит фразы формата «поисковое продвижение Москва» учитываться не будут. Как видно ниже, частота спроса стала значительно меньше.
При этом словоформы все еще учитываются. Это означает, что сюда могут попасть запросы «поисковому продвижению». Для того, чтобы зафиксировать форму слова используем «!» перед ним, как в примере ниже.
Оператор «кавычки, квадратные скобки и знак восклицания» («») — фиксирует количество и порядок слов в запросе, а также словоформу первого слова, перед которым стоит знак восклицания.
В результате можно максимально точно определить, как часто пользователи интересуются той или иной тематикой в поисковой системе Яндекс.