Вордстат ассистент
Содержание:
- Программы парсеры
- Кейс №4
- Yandex Wordstat Assistant
- Как правильно собирать ключевые слова в Вордстат
- Инструменты для упрощения работы с «Вордстатом» – расширения и программы
- Операторы сервиса «Подбор Слов»
- Сезонность в Яндекс Вордстат — история поисковых фраз
- Для чего нужен парсинг частотности
- Как правильно пользоваться Вордстатом
Программы парсеры
Для точной обработки ключевых слов рекомендуется использовать программные комплексы. Преимущество – они работают напрямую с базами данных Ворстат. Полная версия платная, некоторые разработчики предоставляют демо-режим с ограниченным функционалом.
Кей Коллектор
Программа «Кей Коллектор» популярна среди разработчиков и СЕО-оптимизаторов. Причины – работа с популярными поисковыми системами, сегментация выборок по параметрам пользователя. Предоставляется только на платной основе, стоимость зависит от количества приобретаемых лицензий.
Особенности «Кей Коллектор»:
- Анализируется только актуальная статистика, сбор информации ведется напрямую из баз данных (БД) Яндекса.
- Ключевые слова подбираются по региону, частоте, сезонности.
- Учитываются стоп-слова.
Возможен многопоточный режим работы. Но есть вероятность получения бана или многократного ввода капчи при формировании нескольких потоков запроса информации с одного IP. Возможен сбор информации через Яндекс.Директ, что уменьшает скорость обработки.
Словоёб
Бесплатная альтернатива Кей Коллектор, но с меньшими функциональными возможностями. Отличие – «Словоёб» работает только с Вордстат. При анализе некоторых ключевых фраз могут не учитываться низкочастотные запросы, которые есть в статистике Яндекс.Директ. Глубина эффективного парсинга ограничена 40 страницами.
Особенности программы «Словоёб»:
- меньшие возможности работы с таблицами;
- нет «поисковых подсказок»;
- отсутствует сбор главных страниц выдачи;
- нет позиций по запросам.
Программа подходит для формирования СЯ небольшого проекта. Причина – скорость обработки полученных данных, нет углубленного анализа запросов.
Магадан
Технические ограничения в бесплатном варианте программы:
- нельзя выбрать региональность для запросов;
- отключены фильтры по количеству символов, слов;
- нет импорта файлов со стоп-словами;
- нельзя задавать правила к генерируемым ключевым фразам;
- отключен экспорт КС.
Несмотря на такие ограничения «Магадан» можно использовать для формирования СЯ 1-3 проектов. Но по отзывам пользователей по сравнению с ручной обработкой Вордстата теряются низкочастотные запросы.
Кейс №4
Допустим, перед нами стоит задача быстро собрать теги для категории «Смартфоны» и у нас нет времени чистить огромное облако запросов данной категории от мусора. Чаще всего тегами являются 2 типа интентов – характеристика объекта (белый смартфон, мощный смартфон) и по назначению объекта (смартфон для пожилых, смартфон для девушки). С помощью Вордстата мы можем легко собрать теги 2-го типа – по назначению, так как все такие запросы содержат предлоги. Исходя из этого мы делаем следующую регулярку:
смартфоны (+до|+с|+на) -скачать -игры -интернет -мтс -фото
Так же указываем базовые стоп слова, чтобы не собирать мусор.
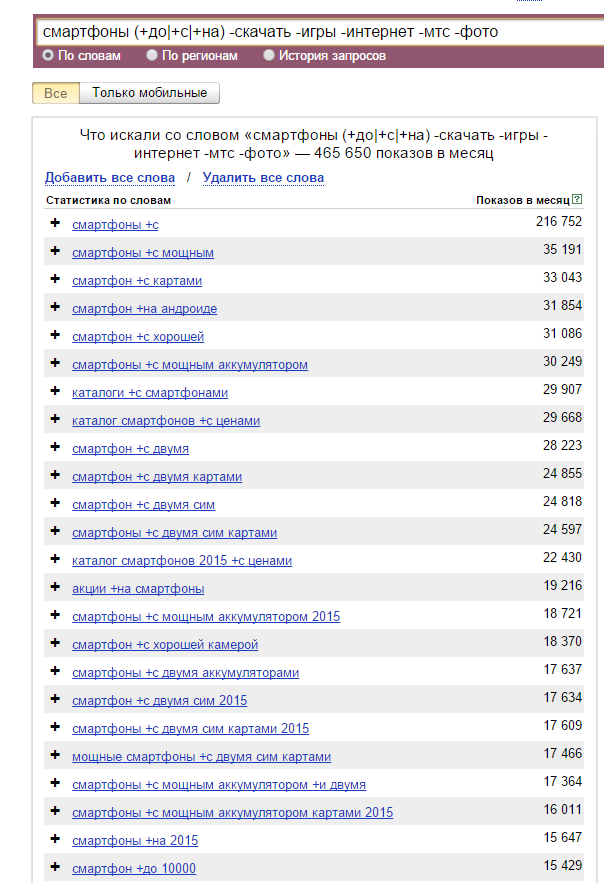
Сразу видны будущие теги – смартфоны на андроиде, с мощным аккумулятором, с хорошей камерой и т.д. Естественно у каждого могут быть индивидуальные проблемы и текущие кейсы не подойдут для решения вашей задачи, но включив логику, вы всегда можете видоизменить наши примеры под ваши нужды.
Все приведенные выше примеры работают в нашем парсере Wordstat – можете сами в этом убедиться. 🙂

Yandex Wordstat Assistant
Yandex Wordstat Assistant – это расширение для браузера, которое при установке будет появляться только если вы будете находится на по адресу Вордстат Яндекса (wordstat.yandex.ru). Данный плагин дает нам возможность ускорить парсинг ключевых слов к себе в таблицу или текстовый файл.
Напротив каждого ключевого слова появится плюсик, и вы можете нажимая на «плюс» добавлять все интересующие ключевые слова в данное расширение, которое появится слева после установки его из магазина расширений.
Далее вы просто нажимаете на кнопку копировать все запросы, они копируются в буфер обмена вашей операционной системы, и далее вы их можете вставить в текстовый документ.
Таким образом, вам не нужно будет каждое ключевое слова выделять вручную и копировать в текстовый документ. Вы просто выделяете все необходимые ключевые слова, одним нажатием нажимаете «копировать» и вставляете в текстовый документ.
Очень удобно и экономит время на данный рутинный, но крайне необходимый и важны процесс.
Далее вбиваете название расширения — Yandex Wordstat Assistant и устанавливаете его.
После установки и активации расширения, оно сразу появится на страницу https://wordstat.yandex.ru слева, и вы сможете им начать пользоваться.

В плагине вы сможете интуитивно довольно быстро разобраться, поскольку он простой в использовании.
В плагине имеется всего 5 кнопок, и давайте каждую из них более подробно разберём:
- Добавить фразы – дает возможность добавить ключевые слова вручную в плагин. Данной опцией я сам не пользуюсь, поскольку не вижу в ней практического применения.
- Копировать список в буфер обмена – все фразы что были добавлены в плагин, за счет данной кнопки можно скопировать в буфер обмена операционной системы, и вставить в текстовый документ. Копирование происходит только ключевых фраз, без частотностей.
- Копировать список с частотностью в буфер обмена – тоже самое что и предыдущая кнопка, только с копированием частотности к каждой ключевой фразе, которые вы добавили в плагин.
- Сортировка – позволяет отсортировать фразы по частотности, алфавиту, порядку добавления и т. д.
- Очистить список – очищает поле плагина от всех добавленных запросов.
Как я писал выше, у списка ключевых фраз при установленном плагине, появляется плюсик слева от каждого запроса, а также появляется ссылка над всеми запросами «Добавить всё».
Если вам необходимо добавить все слова в плагин, то нажимайте данную ссылку, и все ключевые фразы добавятся в плагин. Оттуда вы их может одним нажатием кнопки скопировать в буфер обмена, и вставить в свой текстовый документ или exel.
Как правильно собирать ключевые слова в Вордстат
Вордстат – простой инструмент, с которым вы сможете разобраться меньше, чем за полчаса.
Левая и правая колонка
После введения запроса для проверки в левой колонке вы увидите данные по этому запросу и другим, которые содержат введенный. В правой колонке – похожие:
Учитывайте, что цифра запросов возле верхней строчки левой колонки – это суммарное количество, включающее все нижеследующие запросы.
Правую колонку можно использовать, чтобы увеличить количество релевантных ключевых слов.
Для ускорения подбора слов в Яндекс.Вордстат применяют такие команды:
Поставьте точку возле «по регионам», чтобы просмотреть это:
Тренды и сезонность
Чтобы проверить сезонность, воспользуйтесь «Историей запросов»:
Это поможет своевременно подготовиться к пику в отрасли даже новичку в бизнесе.
С некоторыми поисковыми фразами этот инструмент позволяет найти тренды, то есть те запросы, которых раньше не было в поиске, но которые сейчас набирают популярность:
Если тренд имеет отношение к продажам, количество коммерческих запросов с его использованием также будет увеличиваться.
Поисковые подсказки
Когда запрос становится регулярным, он попадает в поисковые подсказки Яндекса. Точных данных «порога» для этого нет, но это не влияет на полезность этого метода для подбора ключей.
Использовать поисковые подсказки, а не только статистику Яндекс Вордстат стоит, потому что:
- В них быстрее появляются тренды.
- Там можно найти ключи с длинной более 8 слов.
- Не все запросы попадают в Wordstat.
В результате при быстром реагировании на текущие тренды владельцы сайтов получают максимальный трафик по подобным ключевым словам, если своевременно создают необходимые страницы с ответами на запросы пользователей или предугадают последующие запросы.
Коммерческие и информационные ключевые запросы пользователей
Подбор ключевых слов в Вордстат позволяет собрать всевозможные ключевые слова в определенной тематике, но разделить их на коммерческие и информационные – это уже работа для человека, хотя автоматизировать этот процесс также воможно. К коммерческим запросам относятся те, которые содержат слова «сколько стоит», «цена», «купить», «заказать», «с доставкой» и т.д.
Информационные запросы с «своими руками» не подходят для коммерческого продвижения с целью продажи. А вот некоторые другие информационные запросы вполне могут стать гармоничным дополнением к коммерческим.
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
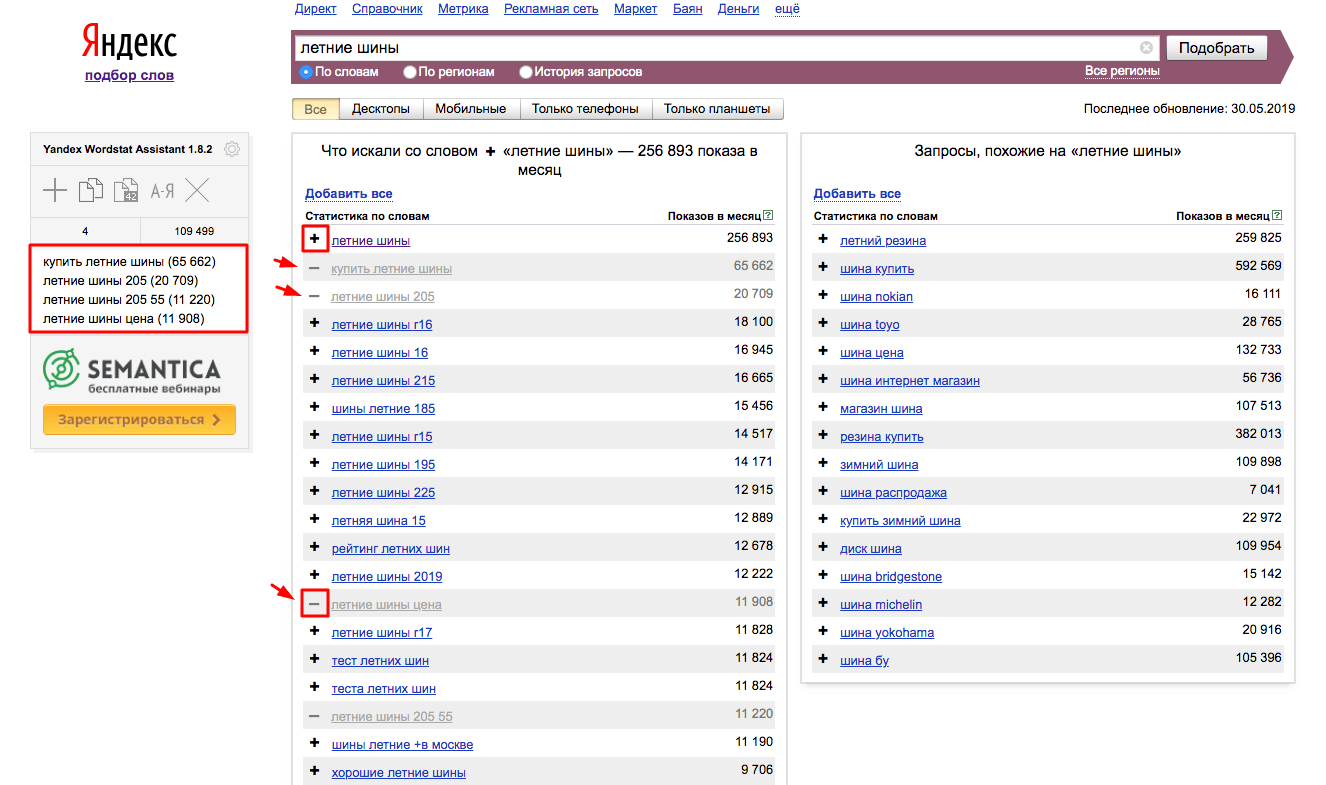
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:
Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/
Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:
Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».
Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:
Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:
Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:
Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:
И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:
Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Операторы сервиса «Подбор Слов»
Для того, чтобы работа в сервисе статистики Яндекса не затягивалась долго и была более точной, существует ряд вспомогательных операторов. Все они используются только в инструменте «По запросам» и вносятся в поле вода поисковой фразы. Рассмотрим каждый оператор по отдельности.
Минус (-)
Оператор предназначен для исключения из списка запросов ненужных слов (так называемые «минус-слова»). Используется в разных случаях, чаще всего для поиска запросов СЯ для коммерческих проектов. Например, сравните левые колонки Вордстата по запросу «внутренняя перелинковка». В первом случае обычная фраза, во втором — исключены запросы со словом «страница»:
Замечу, что минусовали мы в примере слово «страница». В итоге Вордстат исключил все варианты слова с любым падежом.
Плюс (+)
С помощью оператора «плюс» мы принудительно ставим указание сервису на проверку запроса с предлогами и союзами (без этого оператора они исключаются). Вот пример работы этого оператора:
Как видим из примера, в первом случае число запросов с фразой «как готовить омлет из яиц» было самым большим — 712. Это тоже самое, если бы мы набирали запрос в Вордстате — «готовить омлет яиц». Во втором случае число запросов стало меньше, так как мы захотели увидеть их с учетом предлога «из». В третьем их стало еще меньше — появилось слово «как».
В Вордстате по умолчанию при вводе запроса без плюсов в левой колонке дается значение именно с плюсами:
Или и группировка | ()
Оператор «или» позволяет собрать поисковые запросы, слова которых могут иметь разное написание, но одинаковое значение. Например, нам нужны все запросы по созданию блюда «омлет». Для этого мы возьмем сборку трех одинаковых по смыслу словосочетания:
В итоге в левой колонке мы получим все запросы по этим трем фразам.
Ту же самую задачу можно решить, если использовать оператор «группировка». В этом случае нам не нужно будет писать три раза слово «омлет»:
Итак, оператор «или» позволяет нам указать в искомой фразе варианты каких-то слов. Если слов с вариантами несколько, используется «группировка». В итоге получается максимально возможная подборка запросов. Например:
Кавычки («»), восклицательный знак (!)
Используя данный оператор, при подсчете запросов для левой колонки, Вордстат будет считать показы только этой фразы. При подсчете будут также учитываться различные словоформы фразы, а также разный порядок слов. Например, вот какую нам статистику предложит Вордстат по запросу «весенняя капель»:
Оператор «восклицательный знак» учитывает показы по форме слова, которую мы указали, без каких-то изменений (не учитываются различные словоформы):
Небольшое замечание — восклицательный знак ставиться непосредственно перед словом, пробел между оператором «!» и словом не ставится.
В поисковом продвижении используется совместная связка этих операторов. Число показов искомой фразы с этими операторами называется «точной частотой (частотностью) запроса»:
При таком построении искомой фразы с помощью этих операторов мы можем подсчитать запросы, которые не могут менять как сам запрос, так и его словоформы (например, окончания). Это позволит нам с учетом кликабельности сниппета дать примерное число показов продвигаемой страницы по этому запросу в Яндексе (в зависимости от занимаемого места в топе).
Именно поэтому при составлении семантического ядра мы обращаем внимание на точную частотность запроса.
Благодаря специальным операторам, мы можем в Вордстате узнать нужные нам запросы и число их показов практически по любым нашим требованиям. Например, нам нужны запросы по рецептуре блинов с такими ограничениями:
- в запросах должны быть слова «рецепт» и «приготовить»;
- берем разные варианты по типу блюда (блины, блинчики);
- в запросах нет ингредиента «молоко»;
- хотим запросы, чтобы было там точное слово «кефир».
В итоге у нас получается запрос со следующими операторами и соответствующим списком найденных фраз:
Сезонность в Яндекс Вордстат — история поисковых фраз
Интересный раздел, позволяющий познакомиться с динамикой частности выбранной ключевой фразы.
Анализируя данные за несколько лет, вы можете выделить определенную закономерность и понять — существует ли сезонный фактор на интересующий вас товар (или услугу, либо иное явление).
Например, вот история для фразы “москва экскурсии”:
Можно сгруппировать данные по месяцам / неделям, либо — по типу устройства:
История показов по фразе «экскурсии москва». График содержит относительное и абсолютное значение. Можно включить / выключить только абсолютное или только относительное значение. Сам график показов интерактивный:
Здесь же, подробная статистика по датам:
Вы можете смотреть цифры в абсолютных значениях (самый точный вариант):
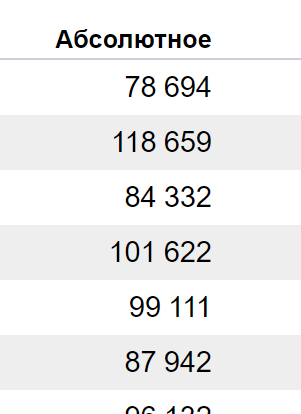
…либо — относительных (в таком случае, учитывается суммарный показ фразы на странице результатов поиска):

Для чего нужен парсинг частотности
Оценка объема трафика по определенным ключевым словам
Частотность в Яндекс.Вордстат отображает количество показов по выбранному ключевому слову за месяц в определенном регионе. С помощью этих данных можно примерно рассчитать потенциальный объем трафика, который можно получать в поисковой выдаче на разных позициях.
Сделать это можно так:
1. Соберите целевую семантику (список ключевиков, по которым вам нужно получать поисковой трафик). Собрать семантику можно с помощью медиапланера от Click.ru.
2. Спарсите частотность ключевых слов. Для примера мы возьмем ключевик «купить Samsung Galaxy в Москве» и проверим его частотность непосредственно в Вордстате. Итого, по данному запросу – 11757 показов в месяц.
3. Найдите в интернете средние значения CTR для каждой из позиций первой страницы поисковой выдачи.
Если ваш сайт добавлен в Яндекс.Вебмастер и работает как минимум несколько месяцев, данные по CTR будут доступны в отчете «Поисковые запросы» → «Все запросы и группы».
К примеру, CTR для второй позиции – 18%. Теперь мы можем посчитать примерный уровень трафика, который можем получить. Формула для расчета:
(Частотность * CTR)/100
Подставляем в формулу наши данные: (11 757 * 18)/100 = 2116.
Конечно, нет гарантии, что мы получим точно такое количество посещений, но для примерной оценки потенциала запроса такие расчеты будут очень полезными.
Еще одна причина для сбора частотности ключей – фильтрация запросов с околонулевой частотностью
Фразы, по которым нет показов (или показов совсем мало – от 1 до 10), лучше убрать из семантического ядра и не тратить время на оптимизацию страниц под такие запросы.
По ним практически не будет трафика, а если запускать контекстную рекламу, объявления получат статус «мало показов» и не будут показываться.
Обратите внимание! Иногда семантику с низкой частотностью не нужно исключать из ядра. Это касается узкоспециализированных тематик, например дорогого медицинского или производственного оборудования
Там ключевые запросы с указанием точной спецификации оборудования могут иметь всего пару запросов в месяц, но приводить максимально целевую и горячую аудиторию.
На что ориентироваться
В зависимости от ниши и типа сайта нижний порог частотности, по которому нужно отсекать бесперспективные запросы, отличается. Для ориентира можете использовать следующие данные:
|
Ниша |
Отсеиваем запросы с частотностью |
|
Узкие тематики |
|
|
Масс-маркет |
до 5 |
|
Информационные ресурсы |
до 30–35 |
При удалении низкочастотных фраз будьте внимательны: НЧ-запросы приводят качественный трафик, поэтому удаляйте фразы аккуратно, оставляя целевые.
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис, вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:
После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:
Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
Давайте теперь смотреть остальные функции интерфейса:
В блоке 1 — переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.В блоке 2 — очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.В блоке 3 — дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.В блоке 4 — выбираем регион/регионы.
По регионам
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:
А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:
История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:
Но самое профессиональное начинается, когда вы работаете с операторами.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».
С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.
С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.
А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
Вспомогательные операторы
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:
Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».
Круглые скобки «()» — группирует использование нескольких операторов.
Квадратные скобки «[]» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:
Как видим, с неправильным порядком фразу почти никто не вводит: