Что
Содержание:
- Удаление лишних слешей в адресе URL
- Что такое индексация сайта
- Настройка файла robots.txt: основные директивы
- Robots.txt для Яндекса и Google
- Блокировка доступа поисковым системам с помощью mod_rewrite
- Как узнать сколько страниц в дополнительном индексе?
- Обозначения и виды директив
- Результаты эксперимента: AJAX
- Результаты эксперимента: варианты JS
- Как запретить роботам доступ к ссылкам на определённом порту
- Связанные статьи:
- Зачем сайт закрывают для индекса?
- Как в Битрикс закрыть сайт от индексации
- Закрыть сайт от индексации в файле .htaccess
Удаление лишних слешей в адресе URL
Например, страница /catalog///stranica.html доступна и открывается. Чтобы избежать такой ситуации и не плодить бесконечное число дублей следует записать следующий редирект:
RewriteEngine on
RewriteBase /
RewriteCond %{HTTP_HOST} !=""
RewriteCond %{THE_REQUEST} ^+\s//+(.*)\sHTTP/+$
RewriteCond %{THE_REQUEST} ^+\s(.*)//+\sHTTP/+$
RewriteRule .* http://%{HTTP_HOST}/%1
RewriteCond %{REQUEST_URI} ^(.*)//(.*)$
RewriteRule . %1/%2
Здесь последовательно используется два правила для того, чтобы удалять многократные слеши из любой части URL: начала, середины, конца.
Это же касается наличия или отсутствия конечного слэша — можно выбрать любой вариант, но только один — это называется «канонический вид». Если движок вашего сайта не умеет работать с этим, то также на помощь придёт mod_rewrite.
Что такое индексация сайта
Опубликованный на страницах сайтов контент собирается заранее и хранится в базе данных поисковой системы.
Называется эта база данных Индексом (Index), а собственно процесс сбора информации в сети с занесением в базу ПС называется «индексацией».
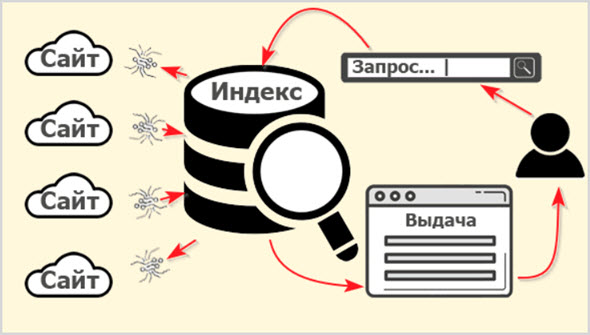
Продвинутые пользователи мгновенно сообразят, получается, что если текст на странице сайта не занесен в Индекс поисковика, так эта информация не может быть найдена и контент не станет доступен людям?
Так оно и есть. Каждый день тысячи веб-мастеров публикуют на своих площадках новые статьи. Однако доступными для поиска эти новые публикации становятся далеко не сразу.
В плане индексации Google работает несколько быстрее нашего Яндекса.
- Публикация на сайте станет доступна в поиске Гугл через несколько часов. Иногда индексация происходит буквально в считанные минуты.
- В Яндексе процесс сбора информации относительно нового контента в интернете происходит значительно медленнее. Иногда новая публикация на сайте или блоге появляется в Яндексе через две недели.
Чтобы ускорить появление вновь опубликованного контента, администраторы сайтов могут вручную добавить URL новых страниц в инструментах Яндекса для веб-мастеров. Однако и это не гарантирует, что новая статья немедленно появится в интернете.
С другой стороны, бывают ситуации, когда веб-страница или отдельная часть контента уже опубликованы на сайте, но вот показывать этот контент пользователям нежелательно по каким-либо причинам.
- Страница еще не полностью доработана, и владелец сайта не хочет показывать людям недоделанный продукт, поскольку это производит негативное впечатление на потенциальных клиентов.
- Существует разновидностей технического контента, который не предназначен для широкой публики. Определенная информация обязательно должна быть на сайте, но вот видеть ее обычным людям пользователям не нужно.
- В статьях размещаются ссылки и цитаты, которые необходимы с информационной точки зрения, но вот находиться в базе данных поисковой системы они не должны. Например, эти ссылки выглядят как неестественные и за их публикацию в проект может быть подвергнут штрафным санкциям.
В общем, причин, почему веб-мастеру не хотелось бы, чтобы целые веб-страницы или отдельные блоки контента, ссылки не были занесены в базы поисковиков, может существовать много.
Давайте разберемся, как задачу управления индексацией решить практически.
Настройка файла robots.txt: основные директивы
Чтобы правильно настроить файл robots.txt, необходимо знать директивы – команды, которые воспринимают роботы поисковых систем. Ниже рассмотрим основные директивы для настройки индексации сайта в файле robots.txt:
| Директива | Назначение |
| User-agent: | Указывает робота поисковой системы, для которого предназначены команды ниже. Названия роботов можно посмотреть в справочной информации, которую предоставляют поисковые системы. |
Директива User-agent: * обозначает, что команды ниже предназначены для всех роботов, для которых нет персональных команд в файле.
Важно соблюдать последовательность команд в файле. В начале прописываются команды для конкретных роботов (Yandex, Googlebot и т.д.), потом – для всех остальных.. Существуют другие директивы, которые используется реже
Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь
Disallow:
Данная директива в файле robots.txt закрывает индексацию определенной страницы или раздела на сайте. Сама страница или раздел указываются от корневой папки сайта, без домена (см. скриншот в начале статьи).
Allow:
Разрешает индексацию определенной страницы или раздела на сайте. Директивы Allow необходимо располагать ниже директив Disallow.
Host:
Указывает главное зеркало сайта (либо с www, либо без www). Учитывается только Яндексом.
Sitemap:
В данной директиве необходимо прописать путь к карте сайта, если она имеется на сайте.
Существуют другие директивы, которые используется реже. Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь.
Частные случаи команд в файле robots.txt
Разберем некоторые команды, которые потребуются Вам в работе:
| Команда | Что обозначает |
| User-agent: Yandex | Начало блока команд для основного робота поисковой системы Яндекс. |
| User-agent: Googlebot | Начало блока команд для основного робота поисковой системы Google. |
| User-agent: *Disallow: / | Данная команда в файле robots.txt полностью закрывает сайт от индексации всеми поисковыми системами. |
| User-agent: *Disallow: /Allow: /test.html | Данные команды закрывают все документы на сайте от индексации, кроме страницы /test.html |
| Disallow: /*.doc | Данная команда запрещает индексировать файлы MS Word на сайте. Если на сайте содержится конфиденциальная информация в файлах определенного типа, имеет смысл закрыть такие файлы от индексации. |
| Disallow: /*.pdf | Данная команда в robots.txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах. |
| Disallow: /basket/ | Команда запрещает индексировать все документы в разделе /basket/. |
| Host: www.yandex.ru | Команда задает для сайта yandex.ru основным зеркалом адрес сайта с www. Соответственно, в поиске с высокой вероятностью будут выводиться адреса страниц с www. |
| Host: yandex.ru | Данная команда задает для сайта yandex.ru в качестве основного зеркала адрес yandex.ru (без www). |
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt», название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
Доступная для пользователей ссылка
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Блокировка доступа поисковым системам с помощью mod_rewrite
На самом деле, всё, что было описано выше, НЕ ГАРАНТИРУЕТ, что поисковые системы и запрещённые роботы не будут заходить и индексировать ваш сайт. Есть роботы, которые «уважают» файл robots.txt, а есть те, которые его просто игнорируют.
С помощью mod_rewrite можно закрыть доступ для определённых ботов
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Google
RewriteCond %{HTTP_USER_AGENT} Yandex
RewriteRule ^ -
Приведённые директивы заблокируют доступ роботам Google и Yandex для всего сайта.
Если, допустим, нужно закрыть для индексирования только одну папку report/, то следующие директивы полностью закроют доступ к этой папке (будет выдаваться код ответа 403 Доступ Запрещён) для сканеров Google и Yandex.
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Google
RewriteCond %{HTTP_USER_AGENT} Yandex
RewriteRule ^report/ -
Как узнать сколько страниц в дополнительном индексе?
Тут все относительно просто. Покажу на примере моего блога. Запрос в гугле
Покажет сколько страниц в основном индексе, сейчас их «About 558 results».
Запрос без знаков «/&», покажет сколько страниц всего в индексе:
Сейчас у меня в индексе всего «About 1,660 results». Выходит у меня 1660-558=1102 страниц в дополнительном индексе. В основном индексе у меня 34% страниц. Честно говоря, это не такой уж и плохой результат. Если же у вас более 50% страниц в основном индексе, то это уже считается хорошим достижением.
Следующий вопрос конечно будет «А как мне посмотреть какие именно страницы в дополнительном индексе?». Тут уже не все так просто, раньше это можно было выяснить с помощью такого запроса:
То есть показать все страницы в индексе, за исключением страниц из основного индекса. Но сейчас такой запрос не работает.
Я догадался выйти из ситуации другим методом. Разобьем сайт на части и проверим в какой из этих частей больше всего страниц в сопливом индексе. Например если вы увлекаетесь тегами, то таких страниц в сопливом индексе должно быть достаточно много, так как там дублирующийся контент, а если еще страница с тегом указывает только на одну-две статьи, то этого контента раз-два и обчелся. Под страницей с тегами подразумеваю страницы с такими адресами: elims.org.ua/blog/tag/span/
Итак, запрос «site:elims.org.ua inurl:/blog/tag/» показал 254 результата, а запрос «site:elims.org.ua/& inurl:/blog/tag/» — 3 результата. Выходит 251 страница с тегами основного подблога «/blog/» находится в сопливом индексе. Теперь я знаю над чем можно поработать. По аналогии можно проинспектировать остальные части сайта.
Обозначения и виды директив
Ниже рассмотрим какие есть директивы в файле Robots.txt
-
User-agent — указание поискового бота, к которому применяются правила. Чтобы выбрать всех роботов – укажите “*”. Директива обязательна для использования, без указания User-gent нельзя использовать какие-либо правила.
Например:
User-agent: * #правила для всех. User-agent: Googlebot #правила только для Google. User-agent: Yandex #правила только для Яндекса.
-
Disallow — директива, которая запрещает сканирование определенных страниц или разделов.
Например:
Disallow: /order/ #закрывает все страницы, которые начинаются с /order/. Disallow: /*sort-order #закрывает все страницы, которые содержат фрагмент “sort-order”. Disallow: /secretiki/ #закрывает все страницы, которые начинаются с /secretiki/.
-
Sitemap — указание ссылки на xml-карту сайта. Если xml-карт сайта несколько – можно указать их все.
Например:
Sitemap: https://inweb.ua/sitemap.xml Sitemap: https://inweb.ua/sitemap-images.xml
-
Allow — позволяет открыть для робота страницу или группу страниц.
Например:
Disallow: /category/ Allo: /category/phones/ Мы закрываем все страницы, которые начинаются с /category/, но открываем /category/phones/
- Clean-param — сообщает Яндексу, что в адресе есть параметры и метки, необязательные при сканировании. Работает только с роботами в Yandex.
-
Спецсимволы:
* – обозначает любое кол-во символов.
Например:
Disallow: * #запрещает сканирование всего сайта. Disallow: *limit #Запрещает сканирование всех страниц, которые содержат “limit”. Disallow: /order/*/success/ #запрещает сканирование всех страниц, которые начинаются с /order/, потом содержат любое кол-во символов, а потом /success/.
-
$ – обозначает конец строки.
Например:
Disallow: /*order$ #запрещает сканирование всех страниц, которые заканчиваются на order.
В каком порядке выполняются правила
Yandex и Google обрабатывает директивы Allow и Disallow не по порядку, в котором они указаны, а сначала сортирует их от короткого правила к длинному, а затем обрабатывает последнее подходящее правило:
User-agent: * Allow: */uploads Disallow: /wp-
Будет прочитана как:
User-agent: * Disallow: /wp- Allow: */uploads
Таким образом, если проверяется ссылка вида: /wp-content/uploads/file.jpg, правило “Disallow: /wp-” ссылку запретит, а следующее правило “Allow: */uploads” её разрешит и ссылка будет доступна для сканирования.
В случае, если директивы равнозначны или противоречат друг-другу:
User-agent: * Disallow: /admin Allow: /admin
Приоритет отдается директиве Allow.
Результаты эксперимента: AJAX
Результат проверки при скрытии посредством технологии AJAX показал, что не в одном из 5 случаев не Яндекс, ни Google не смогли распознать в данном контенте ссылок.
Как видит Google?
Рис. 12. Сохраненная копия в Google.
Видно, что Яндекс и Google воспринимают данный контент как обычный текст и не интерпретирует его как блок ссылок.
Дополнительно произведем поисков текстов ссылок в анкор-листе страниц акцепторов с помощью оператора «allinanchor».
Рис. 13. Проверка наличия текстов ссылок в анкор-листе акцепторов.
В анкор-листе страниц акцепторов фразы из текстов ссылок не были найдены. Это является дополнительным подтверждением того, что поисковые системы не смогли проиндексировать ссылки, скрытые посредством AJAX.
Результаты эксперимента: варианты JS
После переиндексации экспериментальных документов и на основании изучения текстовой версии сохраненных копий документов в Яндексе и Google, был сделан вывод о том, какие варианты скрытия ссылок поисковые системы не смогли распознать.
Как видит Google?

Рис. 7. Сохраненная копия в Google.
Яндекс и Google распознали в данном блоке ссылки только в 2 из 5 случаев, когда в коде в явном виде был указан URL акцептора. В остальных случаях поисковые системы интерпретировали данные блоки как обычный текст.
На основании полученных данных можно сделать вывод о том, что представленные ниже варианты JavaScript позволяют скрывать ссылки и прочий контент от индексации.
1. <input type=»button» value=»текст» class=»button_buy» onclick=»javascript:window.location=’/samostoyatelno/stati/indeksatsiya/301-redirekt.html'»/>
2. <a href=»#» onclick=»javascript:window.open(‘ht’+’tp’+’://’+’www’+’.pixel’+’plus’+’.’+’ru’)»>анкор</a>
3. <a href=»#» onclick=»javascript:window.location=’/samostoyatelno/stati/indeksatsiya/301-redirekt.html'» >анкор</a>
В качестве дополнительной проверки эффективности методики произведем поиск указанных в эксперименте текстов ссылок в анкор-листе акцепторов используя оператор расширенного поиска Google — allinanchor.
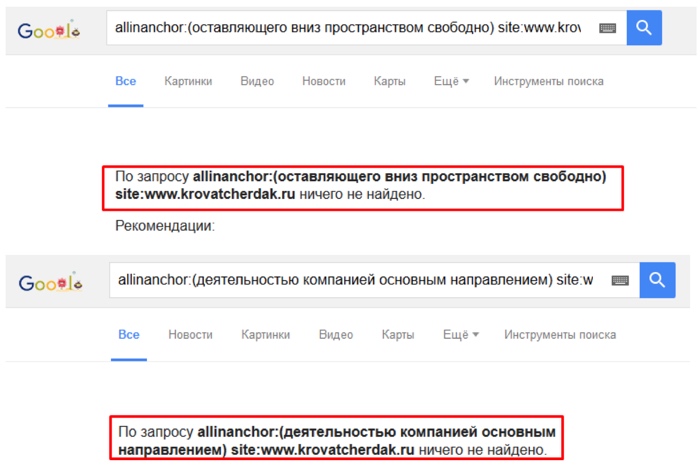
Рис. 8. Проверка наличия текстов ссылок в анкор-листе акцепторов.
Как можно видеть, в анкор-листе страниц акцепторов также отсутствуют тексты анализируемых ссылок.
Как запретить роботам доступ к ссылкам на определённом порту
Предположим, есть частный веб-сервер, настроенный на нетрадиционный порт (скажем, 6677). Все люди могут иметь доступ ко всем URL-адресам сайта на порту 6677. Ссылки с mysite.ru:6677 также проиндексированы Google, что может быть нежелательно.
Итак, как я могу запретить доступ к страницам сайта в robots.txt на нестандартном порте?
Если вы хотите запретить сканеру доступ к example.com:6677 с помощью robots.txt, вам просто нужно разместить файл robots.txt на соответствующем порту, то есть: http://example.com:6677/robots.txt
Спецификация не позволяет указывать порт в самом файле robots.txt. Все указанные пути используют тот же протокол, номер порта и хост, с которого осуществляется доступ к файлу.
Но, как уже говорилось в этой статье, запрет в robots.txt необязательно предотвращает индексирование URL-адреса; он предотвращает попадание в индекс поисковых систем.
То есть, предыдущий совет подойдёт для тех, у кого сайт на нестандартном порту является отдельным виртуальным хостом со своим собственным содержимым.
Но если один и тот же сайт доступен как с порта 80, так и с порта 6677, но только порт 6677 должен быть заблокирован для поисковых роботов, то предыдущий способ не подойдёт. Поскольку оба порта обращаются к одному и тому же сайту, они оба будут использовать общий файл robots.txt, и поэтому оба сайта будут заблокированы, если только разные файлы robots.txt не показываются зависимости от того, какой порт использовался для доступа к сайту.
В такой ситуации необходимо проверить порт в серверном скрипте и отправить клиенту соответствующий тег META или заголовок HTTP-ответа. В PHP вы можете сделать это примерно так:
<?php
// Блокируем роботов от доступа к порту 6677
if ($_SERVER == '6677') {
header('X-Robots-Tag: noindex');
}
?>
Помните, что все заголовки должны выводиться строго до отправки других данных, поскольку после отправки данных заголовки уже отправлены и изменить их позже невозможно — это вызовет ошибку в PHP.
Можно пойти кардинально и запретить доступ поисковым систем к определённому порту, добавив примерно следующие правила в файле .htaccess:
# Блокируем доступ Google к порту 6677:
RewriteCond "%{SERVER_PORT}" "^6677$"
RewriteCond %{HTTP_USER_AGENT} Google
RewriteRule .* -
# Блокируем доступ Yandex к порту 6677:
RewriteCond "%{SERVER_PORT}" "^6677$"
RewriteCond %{HTTP_USER_AGENT} Yandex
RewriteRule .* -
Связанные статьи:
- Как защититься от спама через формы обратной связи (80.9%)
- Как в mod_rewrite блокировать по Referer, User Agent, URL, строке запроса, IP и в их комбинациях (59.2%)
- Какую информацию собирает Google — как просмотреть и удалить (54%)
- А как долго на ваших сайтах «залипают» пользователи? (50.4%)
- Как сбросить пароль WordPress без доступа к почте (50.4%)
- Не работает перенаправление на HTTPS в WordPress (RANDOM — 50.4%)
Зачем сайт закрывают для индекса?
Есть несколько причин, которые заставляют вебмастеров скрывать свои проекты от поисковых роботов. Зачастую к такой процедуре они прибегают в двух случаях:
-
- Когда только создали блог и меняют на нем интерфейс, навигацию и прочие параметры, наполняют его различными материалами. Разумеется, веб-ресурс и контент, содержащийся на нем, будет не таким, каким бы вы хотели его видеть в конечном итоге. Естественно, пока сайт не доработан, разумно будет закрыть его от индексации Яндекса и Google, чтобы эти мусорные страницы не попадали в индекс.
Не думайте, что если ваш ресурс только появился на свет и вы не отправили поисковикам ссылки для его индексации, то они его не заметят. Роботы помимо ссылок учитывают еще и ваши посещения через браузер.
- Иногда разработчикам требуется поставить вторую версию сайта, аналог основной на которой они тестируют доработки, эту версию с дубликатом сайта лучше тоже закрывать от индексации, чтобы она не смогла навредить основному проекту и не ввести поисковые системы в заблуждение.
- Когда только создали блог и меняют на нем интерфейс, навигацию и прочие параметры, наполняют его различными материалами. Разумеется, веб-ресурс и контент, содержащийся на нем, будет не таким, каким бы вы хотели его видеть в конечном итоге. Естественно, пока сайт не доработан, разумно будет закрыть его от индексации Яндекса и Google, чтобы эти мусорные страницы не попадали в индекс.
Как в Битрикс закрыть сайт от индексации
Для этого нужно использовать метатег <meta name=»robots» content=»noindex, nofollow»>. Для скрытия какой-либо страницы от индексирования нужно, добавляя или изменяя условия, выбрать пункт «Закрыть от индексации».
Кроме того, возможно отключение индексации всех страниц с подключенным компонентом sotbit:seo.meta. Для этого нужно зайти в общие настройки модуля SEO умного фильтра и включить опцию «Отключить индексацию всех страниц».
Приоритетными будут настройки индексации в условии, а не эта опция. То есть в случае отключения в настройках условия опции «Закрыть от индексации» страница, удовлетворяющая этому условию, будет проиндексирована.
Закрыть сайт от индексации в файле .htaccess
Способ первый
В файл .htaccess вписываем следующий код:
SetEnvIfNoCase User-Agent "^Googlebot" search_bot SetEnvIfNoCase User-Agent "^Yandex" search_bot SetEnvIfNoCase User-Agent "^Yahoo" search_bot SetEnvIfNoCase User-Agent "^Aport" search_bot SetEnvIfNoCase User-Agent "^msnbot" search_bot SetEnvIfNoCase User-Agent "^spider" search_bot SetEnvIfNoCase User-Agent "^Robot" search_bot SetEnvIfNoCase User-Agent "^php" search_bot SetEnvIfNoCase User-Agent "^Mail" search_bot SetEnvIfNoCase User-Agent "^bot" search_bot SetEnvIfNoCase User-Agent "^igdeSpyder" search_bot SetEnvIfNoCase User-Agent "^Snapbot" search_bot SetEnvIfNoCase User-Agent "^WordPress" search_bot SetEnvIfNoCase User-Agent "^BlogPulseLive" search_bot SetEnvIfNoCase User-Agent "^Parser" search_bot
Каждая строчка для отдельной поисковой системы
Способ второй и третий
Для всех страниц на сайте подойдет любой из вариантов — в файле .htaccess прописываем любой из ответов сервера для страницы, которую нужно закрыть.
- Ответ сервера — 403 Доступ к ресурсу запрещен -код 403 Forbidden
- Ответ сервера — 410 Ресурс недоступен — окончательно удален
Способ четвертый
Запретить индексацию с помощью доступа к сайту только по паролю
В файл .htaccess, добавляем такой код:
AuthType Basic AuthName "Password Protected Area" AuthUserFile /home/user/www-auth/.htpasswd Require valid-user
home/user/www-auth/.htpasswd - файл с паролем - пароль задаете Вы сами.
Авторизацию уже увидите, но она пока еще не работает
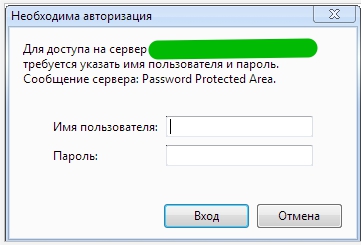
Теперь необходимо добавить пользователя в файл паролей:
htpasswd -c /home/user/www-auth/.htpasswd USERNAME
USERNAME это имя пользователя для авторизации. Укажите свой вариант.