«вкалывают роботы»: что такое robots.txt и как его настроить
Содержание:
Краулинговый бюджет
Как работает Crawler?
Crawler (веб-паук, краулер) — один из составляющих любой поисковой машины, краулер предназначен для поиска и внесения в собственную базу данных веб-страниц найденных на просторах всемирной паутины.
У каждого краулера есть квота для сайтов, которая ограничивается определенным количеством запросов в сутки для обхода новых и уже существующих страниц. Не каждому веб-мастеру это известно, хотя данная информация давно была предоставлена специалистами из поисковых систем.
Секрет, как я упоминал выше, кроется в том, что необходимо сохранить данную квоту и не тратить ее на переобход ненужных страниц. «Приручить» веб-паука и заставить играть по своим правилам, можно с помощью дополнительных инструкций и запрета индексации динамических параметров.
Снижение количества обращений к сайту от поисковых систем
Почему это важно?
Ускорение индексации сайта в поисковых системах Яндекс и Google, кроется в соблюдении простых правил, таких как:
- Грамотная настройка правил robots.txt
- Анализ данных из панели веб-мастера
Поисковая система Яндекс за последний год, существенно улучшила инструментарий для российских веб-мастеров. Используйте данную возможность на полную катушку.
Яндекс.Вебмастер отдает в распоряжение владельцев сайтов, гораздо больше информации, чем в 2010-2012 годах. На основе статистики можно составить целую стратегию по увеличению скорости индексации.
Составление по-настоящему эффективных правил для поисковых машин базируется на запрете обхода ненужного контента, в который входят, такие вещи как: панель администратора, utm-метки, динамические данные и огромное количество других похожих страниц.
Именно в запрете индексации страниц дублей и ненужного контента, кроется скорость индексации, потому как из 5 ежедневных запросов от поисковика, все 5 из них уйдут на просмотр наиболее важных страниц.
Директива Clean-Param
Динамическая директива Clean-Param является межсекционной, это означает, что ее можно использовать в любой строчке robots.txt и неограниченное число раз. Если на сайте используются динамические параметры страниц, которые никак не влияют на их содержимое, мы можем закрыть такие параметры с помощью данной директивы.
Как использовать Clean-Param?
Для начала с помощью инструментов для веб-мастера необходимо отыскать динамические параметры. Они выглядят примерно так:
Скриншот из панели Яндекс.Вебмастер
Как с помощью robots.txt запретить обход таких параметров? Если необходимо использовать запрет для конкретных директорий, пишем:
Если динамических параметров несколько, воспользуемся амперсандом:
Если требуется отрезать параметр от всех страниц на сайте, достаточно написать в robots.txt:
Это же правило отлично работает для utm-меток:
Таким образом, вы существенно сэкономите бюджет обхода, тем самым, повысите обход наиболее важных и новых страниц на своем сайте. Внедряйте!
Директивы robots
В роботс.тхт прописываются определённые правила для веб-краулеров. Рассмотрим их подробнее.
User-Agent
Визитная карточка для ботов. Обязательная команда, определяющая конкретную поисковую программу — сейчас известно до 302 краулеров. Если в конце директивы прописан знак *, то по умолчанию разрешение на индексацию получают все известные боты. User-Agent — это начало любого роботс.тхт.

Disallow
Второе распространённое правило, используемое в robots. Оно запрещает индексировать конкретную страницу (-цы) или разделы блога. Обычно ботам не дают доступа к страницам пагинации, личным данным, результатам внутреннего поиска, логам и служебным page. Например, вот так выглядит запрет на индексацию всего сайта для Yandex bot.

Эту строку используют в процессе различных доработок сайта, когда веб-мастеру по каким-то причинам не хочется засвечивать ресурс.
А вот так выглядит запрет только на категории ресурса:

Allow
Разрешающая директива, противоположная Disallow. Она позволяет ботам читать коды конкретных страниц или категорий веб-ресурса. Например, с помощью Allow удастся открыть для индексации фотоальбом, PDF, определённый page.

Sitemap
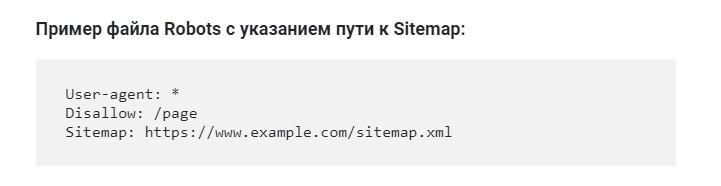
Означает в роботсе расположение карты сайта XML. Она крайне важна для нормальной индексации ресурса ПС, поэтому надо обязательно указывать её полный урл. Именно в Сайтмапе показана структура площадки со внутренними ссылками, даты создания материала и его редактирования. Вот, как надо указывать путь к Sitemap в robots.
Clean-param
Запрещает веб-краулерам обходить дубли и зеркала, страницы с индивидуальными префиксами, UTM-метками, идентификаторами пользователей и сессий. Указывая данную директиву, веб-мастера улучшат обход сайта поисковиками. Также значительно снизится нагрузка на сервер. Пример прописания Clean-param:

Есть также директивы Host и Crawl-delay, но они более не поддерживаются Google и Yandex.
Специальные обозначения
Для того чтобы директивы были более понятны поисковым краулерам, используются специальные обозначения.
Звёздочка * обозначает доступ ко всем компонентам файла. Например, вот как прописывается запрет для ботов, которые не должны индексировать любые документы с расширением .gif в папке /catalog.

Доллар $ ограничивает символ звёздочки *. Если нужно запретить всё содержимое файла /catalog, но при этом нельзя закрыть от индексации url, используется как раз этот символ. Вот пример.

- Слэш / показывает, что какая-то часть кода закрывается от индексации роботом. Например, если знак стоит в директиве Disallow так: Disallow: /, это запрет на обнаружение сайта ПС. Но это практически не используют, обычно просто запрещают какую-то отдельную папку или файл — Disallow: /catalog/. А если вот так — Disallow: /catalog, то все ссылки на веб-ресурсе, начинающиеся на /catalog, не индексируются.
- Решётка # используется авторами кода для добавления заметок и рекомендаций — обычно для других веб-мастеров или для себя. Содержимое после этого знака не учитывается ПС при сканировании. Вот как это выглядит.

Robots.txt для WordPress
Для создания файла нам нужно точно так же забросить robots.txt в корень сайта. Изменять его содержимое в таком случае можно будет с помощью все тех же FTP и файловых менеджеров.
Есть и более удобный вариант – создать файл с помощью плагинов. В частности, такая функция есть у Yoast SEO. Править роботс прямо из админки куда удобнее, поэтому сам я использую именно такой способ работы с robots.txt.
Как вы решите создать этот файл – дело ваше, нам важнее понять, какие именно директивы там должны быть. На своих сайтах под управлением WordPress использую такой вариант:
User-agent: * # правила для всех роботов, за исключением Гугла и Яндекса
Disallow: /cgi-bin # папка со скриптами
Disallow: /? # параметры запросов с домашней страницы
Disallow: /wp- # файлы самой CSM (с приставкой wp-)
Disallow: *?s= # \
Disallow: *&s= # все, что связано с поиском
Disallow: /search/ # /
Disallow: /author/ # архивы авторов
Disallow: /users/ # и пользователей
Disallow: */trackback # уведомления от WP о том, что на вас кто-то ссылается
Disallow: */feed # фид в xml
Disallow: */rss # и rss
Disallow: */embed # встроенные элементы
Disallow: /xmlrpc.php # WordPress API
Disallow: *utm= # UTM-метки
Disallow: *openstat= # Openstat-метки
Disallow: /tag/ # тэги (при наличии)
Allow: */uploads # открываем загрузки (картинки и т. д.)
User-agent: GoogleBot # для Гугла
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js # открываем JS-файлы
Allow: /*/*.css # и CSS
Allow: /wp-*.png # и картинки в формате png
Allow: /wp-*.jpg # \
Allow: /wp-*.jpeg # и в других форматах
Allow: /wp-*.gif # /
Allow: /wp-admin/admin-ajax.php # работает вместе с плагинами
User-agent: Yandex # для Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # чистим UTM-метки
Clean-Param: openstat # и про Openstat не забываем
Sitemap: # прописываем путь до карты сайта
Host: https://site.ru # главное зеркало
Внимание! При копировании строк в файл – не забудьте удалить все комментарии (текст после #). Такой вариант robots.txt наиболее популярен среди вебмастеров, которые используют WP
Идеальный ли он? Нет. Вы можете попытаться что-то добавить или наоборот убрать. Но учтите, что при оптимизации текстовика роботов нередки ошибки. О них мы поговорим далее
Такой вариант robots.txt наиболее популярен среди вебмастеров, которые используют WP. Идеальный ли он? Нет. Вы можете попытаться что-то добавить или наоборот убрать. Но учтите, что при оптимизации текстовика роботов нередки ошибки. О них мы поговорим далее.
Синтаксис robots.txt
Как настроить robots.txt? Примерно так может выглядеть блок robots.txt, ориентированный на Google.

Комментарии
Комментарии — это строки, которые полностью игнорируются поисковыми системами. Они начинаются со знака #. Они нужны для заметок о том, какие действия выполняют строки файла. Рекомендуется документировать каждую директиву в robots.txt, чтобы она могла быть удалена за ненадобностью или отредактирована.
Указания User-agent
Это блок, который даёт указания поисковым системам и роботам, используя директиву User-agent. Например, если вы хотите установить правила отдельно для Яндекса и Google. Тем не менее, он не применим для Facebook и рекламный сетей — на них можно повлиять только через специальный токен с применением особых правил.
Каждый робот предусматривает собственный user-agent токен.
Краулеры сперва учитывают наиболее точные директивы, разделённые дефисом, а затем переходят к объемлющим. Так, Googlebot News сначала выполнит указания для User-agent «googlebot-news», а потом уже «googlebot» и впоследствии «*».
Наиболее распространённые роботы в российском сегменте — это:
Конечно, этот список далеко не исчерпывающий. Чтобы ознакомиться с полным перечнем используемых поисковиками и другими системами роботов, лучше прочитайте их документацию.
Наименования роботов в robots.txt нечувствительны к регистру. «Googlebot» и «googlebot» вполне взаимозаменяемы.
Шаблоны адресов
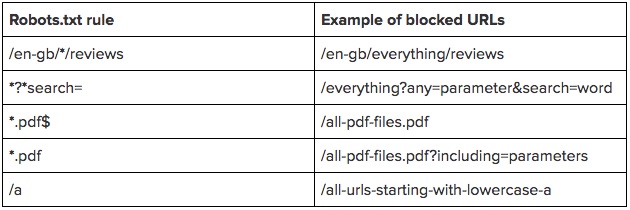
Вместо того, чтобы прописывать большой перечень конечных URL для блокировки, достаточно указать только шаблоны адресов.
Для эффективного использования такой функции понадобится два знака:
* — данный символ группировки обозначает любое количество символов. Его лучше располагать в начале или внутри адреса, но не в конце. Можно использовать сразу несколько групповых символов — например, «Disallow: */notebooks?*filter=». Правила с полными адресами не должны начинаться с данного символа.
$ — знак доллара означает конец адреса. Так, «Disallow: */item$» будет соответствовать URL, заканчивающемуся на «/item», но не «/item?filter» или подобным.
Обратите внимание, что эти правила уже чувствительны к регистру. Если вы запрещаете адреса с параметром «search», роботы всё ещё будут просматривать адреса, содержащие «Search»
Директивы работают только с телом адреса и не включают протокол или сам домен. Слэш в начале адреса означает, что данная директория располагается сразу после основного каталога. Например, «Disallow: /start» будет соответствовать «www.site.ru/start
Пока вы не добавите * или в начало директивы, она не будет ничему соответствовать. «Disallow: start» не будет иметь смысла — роботы её не поймут.
Чтобы наглядно продемонстрировать правило, приведём таблицу примеров:
Sitemap.xml
Директива Sitemap в robots.txt говорит поисковикам, где найти карту сайта в формате XML. Это поможет им лучше ориентироваться в структуре страниц.
Для Sitemap вы должны указать полный путь, как это сделано у нас: «Sitemap: https://www.calltouch.ru/sitemap.xml». Также следует отметить, что Sitemap не всегда располагается на том же домене, что и весь сайт.
Поисковые роботы прочитают указанные в robots.txt карты сайтов, но они не появятся в том же Google Search Console, пока вы не дадите на это разрешение.
Host
Этот элемент раньше работал исключительно как инструкция для Яндекса, другим поисковым системам она была непонятна. Он указывал роботу Яндекса на главное зеркало сайта, и система рассматривала его в приоритетном порядке.
Директива Host уже не поддерживается Яндексом, решение об этом было принято еще в 2018 году. Теперь вместо нее схожий функционал выполняет раздел «Переезд сайта», доступный в Яндекс.Вебмастере.
Использование Google Search Console (GSC)
Как говорилось ранее, часть функций, которые можно указать для роботов Яндекса в robots.txt, для роботов Google надо указывать в Google Search Console.
Чтобы указать главное зеркало в Google необходимо подтвердить оба зеркала (www.site.ru и site.ru) в GSC. Зайти в настройки сайта (знак шестеренки), там выбрать ссылку «Настройка сайта» и в блоке «Основной домен» выбрать главное зеркало и сохранить изменения.

Чтобы ограничить скорость сканирования сайта роботами Google необходимо подтвердить сайт в GSC. Зайти в настройки сайта (знак шестеренки), там выбрать ссылку «Настройка сайта», в блоке «Частота сканирования» выбрать пункт «Ограничить максимальную скорость сканирования Google» и выставить приемлемое значение, после чего сохранить изменения.

Для того чтобы задать, как Google будет обрабатывать параметры в url-адресах сайта необходимо подтвердить сайт в GSC. Зайти в раздел «Сканирование» – «Параметры URL», нажать на кнопку «Добавление параметра», заполнить соответствующие поля и сохранить изменения.
В поле «Параметр» добавляется сам параметр. Это поле является регистрозависимым.
В поле «Изменяет ли этот параметр содержание страницы, которое видит пользователь?», вне зависимости от реального значения параметра, рекомендуем выбирать пункт «Да, параметр изменяет, реорганизует или ограничивает содержимое страницы», так как при выборе варианта «Нет, параметр не влияет на содержимое страницы (например, отслеживает использование) есть вероятность того что, одна страница с параметром все же попадет в индекс.
Выбор в поле «Как этот параметр влияет на содержимое страницы?» влияет только на то как этот параметр будет отображаться в списке других параметров в GSC, поэтому допускается выбор любого значения.
В блоке «Какие URL содержащие этот параметр, должен сканировать робот Googlebot?» выбор должен делаться исходя из того, что за параметр вводится. Если это метки для отслеживания, рекомендуется выбирать «Никакие URL». Если это какие-то GET параметры для продвигаемых страниц, выбирать стоит «Каждый URL».

Если робот Google уже нашел какие-либо параметры на сайте, то вы увидите список этих параметров в таблице и сможете посмотреть примеры таких страниц.
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «YandexMedia», то общие директивы user-agent не используются для него. Пример написания:
User-agent: YandexBot Disallow: /cart # будет использоваться только основным индексирующим роботом Яндекса
Disallow/Allow. Это запрет/разрешение индексации конкретного документа или разделу. Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Allow». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексацию страницы — просто введи относительный путь до нее (Disallow: /blog/post-1).
User-agent: Yandex Disallow: / Allow: /articles # Запрещаем индексацию сайта, кроме 1 раздела articles
Регулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую). Знак доллара означает прерывание. Примеры использования:
Disallow: /page* # запрещает все страницы, конструкции http://site.ru/page Disallow: /arcticles$ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/new
Директива Sitemap. Если вы используете карту сайта (sitemap.xml) – то в robots.txt она должна указываться так:
Sitemap: http://site.ru/sitemap.xml
Директива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта). Данное правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Host: site.ru
Crawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow/Allow.
Crawl-delay: 5 # таймаут в 5 секунд
Clean-param. Указывает поисковому боту, что не нужно скачивать дополнительно дублирующую информацию (идентификаторы сессий, рефереров, пользователей). Прописывать Clean-param следует для динамических страниц:
Clean-param: ref /category/books # указываем, что наша страница основная, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с параметрами
Главное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
User-agent: Yandex Disallow: /cart Allow: /cart/images Sitemap: http://site.ru/sitemap.xml Host: site.ru Crawl-delay: 2
Используемые директивы
User-agent
Все блоки правил начинаются с директивы User-agent, в которой указывается название робота, для которого задается правило. Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например, при следующей записи правило будет применено только к основному индексирующему боту Яндекса:
User-agent: YandexBot
Правило будет применено ко всем роботам Яндекса и Google:
User-agent: Yandex User-agent: Googlebot
Правило будет применено вообще ко всем роботам:
User-agent: *
Disallow и Allow
Директивы используются, чтобы запретить и разрешить доступ к определенным разделам сайта.
Например, можно запретить индексацию всего сайта (Disallow: /), кроме определенного каталога (Allow: /catalog):
User-agent: имя_бота Disallow: / Allow: /catalog
Запретить индексацию страниц, начинающихся с /catalog, но разрешить для страниц, начинающихся с /catalog/auto и /catalog/new:
User-agent: имя_бота Disallow: /catalog Allow: /catalog/auto Allow: /catalog/new
В каждой строке указывается только одна директория. Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
С помощью Disallow можно ограничить доступ к сайту для нежелательных ботов, тем самым снизив создаваемую ими нагрузку. Например, чтобы запретить доступ ко всему сайту для MJ12bot и AhrefsBot — ботов сервиса majestic.com и ahrefs.com — используйте:
User-agent: MJ12bot User-agent: AhrefsBot Disallow: /
Аналогичным образом устанавливается блокировка и для других ботов (скажем, DotBot, SemrushBot и других).
Примечания:
- Пустая директива Disallow: равнозначна Allow: /, то есть «не запрещать ничего».
- В директивах может использоваться символ $ для обозначения точного соответствия указанному параметру. Например, запись Disallow: /catalog аналогична Disallow: /catalog * и запретит доступ ко всем страницам с /catalog (/catalog, /catalog1, /catalog-new, /catalog/clothes и др.).Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
Sitemap
При использовании файла sitemap.xml для описания структуры сайта, можно указать путь к нему с помощью соответствующей директивы:
User-agent: * Disallow: Sitemap: https://mydomain.com/путь_к_файлу/mysitemap.xml
Можно перечислить несколько файлов Sitemap, каждый в отдельной строке.
Host
Директива используется для указания роботам Яндекса основного зеркала сайта и полезна, когда сайт доступен по нескольким доменам.
User-agent: Yandex Disallow: /catalog1$ Host: https://mydomain.com
Примечания:
- Директива Host может быть только одна; если в файле указано несколько, роботом будет учтена только первая.
- Необходимо указывать протокол https, если он используется. Если вы используете http, зеркало можно записать в виде mydomain.com
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Crawl-delay
Директива устанавливает минимальный интервал в секундах между обращениями робота к сайту, что может быть полезно для снижения создаваемой роботами нагрузки. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами (разделитель — точка).
User-agent: Yandex Disallow: Crawl-delay: 0.5
Примечания:
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Clean-param
Директива используется для робота Яндекса. Она позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах (это могут быть идентификаторы сессий, пользователей, рефереров), чтобы робот не индексировал одно и то же содержимое повторно, повышая тем самым нагрузку на сервер.
Например, на сайте есть страницы:
www.mydomain.ru/news.html?&parm1=1&parm2=2 www.mydomain.ru/news.html?&parm2=2&parm3=3
По факту по обоим адресам отдается одна и та же страница — www.mydomain.ru/news.html, при этом в URL присутствуют дополнительные динамические параметры.
Чтобы робот не индексировал каждую подобную страницу, можно использовать директиву:
User-agent: Yandex Disallow: Clean-param: parm1&parm2&parm3 /news.html
Через знак & указываются параметры, которые робот должен игнорировать. Далее указывается страница, для которой применяется данное правило
Структура robots.txt
Строение файла выглядит просто. Он включает ряд блоков, адресованных конкретным ботам-поисковикам. В этих блоках прописываются директивы (команды) для управления ходом индексации.
Дополнительно можно проставлять комментарии. Чтобы они игнорировались поисковиком, нужно использовать знак #. Каждый комментарий начинается и заканчивается этим символом. Кроме того, не рекомендуется вставлять символ комментария внутри директивы.
Robots.txt создаётся одним из удобных для вас методов:
- вручную с использованием текстового редактора, после чего он сохраняется с расширением *. txt.
- автоматически с применением онлайн-программ.
Большинство специалистов работают с файлом вручную — процесс достаточно прост, занимает немного времени, но при этом вы будете уверены в правильности его написания.
В любом случае, автоматически сформированные файлы обязательно подлежат проверке, ведь от этого зависит, насколько хорошо будет функционировать ваш сайт.
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt», название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
Доступная для пользователей ссылка
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».