Регионы вордстат города и районы россии по алфавиту
Содержание:
- Инструменты для упрощения работы с «Вордстатом» – расширения и программы
- Как правильно пользоваться Вордстатом
- Описание
- Как автоматизировать подбор ключевых слов в Вордстате
- Пошаговый алгоритм работы с сервисом:
- Оффлайн парсеры
- Для чего нужен парсинг частотности
- Другие возможности сервиса
- Как правильно собирать ключевые слова в Вордстат
- Операторы сервиса «Подбор Слов»
- Яндекс Вордстат — ключевые моменты
- Как найти популярные ключевые слова в Яндексе
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:

Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/

Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:

Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».

Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:

Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:

Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:

Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:

И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:

Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис, вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:
После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:
Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
Давайте теперь смотреть остальные функции интерфейса:
В блоке 1 — переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.В блоке 2 — очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.В блоке 3 — дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.В блоке 4 — выбираем регион/регионы.
По регионам
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:
А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:
История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:
Но самое профессиональное начинается, когда вы работаете с операторами.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».
С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.
С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.
А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
Вспомогательные операторы
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:
Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».
Круглые скобки «()» — группирует использование нескольких операторов.
Квадратные скобки «[]» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:
Как видим, с неправильным порядком фразу почти никто не вводит:
Описание
Wordstat Yandex или Подбор слов — это бесплатный сервис Яндекса, предназначенный для оценки пользовательского интереса к различным тематикам и подбора ключевых слов для SEO-оптимизации и контекстной рекламы. Кроме того, с помощью Яндекс Вордстат можно оценить сезонность и географическую зависимость поисковых запросов.
Особенности работы сервиса
- Wordstat не работает без регистрации. Ранее такая возможность была, однако с недавних пор инструмент запускается только после авторизации в Яндекс. Почте.
- Вордстат фильтрует пользователей. Под фильтры системы можно попасть из-за нарушения лицензии на использование Яндекса, а также из-за DDOS-атак на сервис с вашего компьютера в результате деятельности вируса. Стоит отметить, что в качестве атаки на сервер может быть воспринята работа специальных парсеров – программ, собирающих ключевые словосочетания в автоматическом режиме (например, Key Collector).
- Периодически при работе может выскакивать Captcha, приостанавливающая работу с Вордстатом. Возникает это из-за некорректного IP-адреса (для пользователей из не постсоветских стран), закрытых файлов cookie или отсутствии поддержки JS-скриптов на компьютере.
В Яндекс Wordstat доступны срезы по типам устройств пользователей:
- Срез «Десктопы» для запросов, введенных с компьютеров и ноутбуков,
- Срез «Мобильные» для запросов, введенных с планшетов и смартфонов,
- Срез «Только телефоны» – запросы исключительно со смартфонов,
- Срез «Только планшеты» – запросы, введенные только с планшетов.
Операторы Вордстат
- Оператор «-» (минус-слово). Позволяет исключить слово из статистики запросов. Применяется отдельно для каждого слова. Чтобы исключить словосочетание, необходимо добавлять оператор минус перед каждым словом в поисковой строке сервиса.
- Оператор «+» (учет стоп-слов). Позволяет учитывать в статистике союзы и предлоги во всех словоформах, которые игнорируются поисковой системой. При детализации запроса (левая колонка) оператор «+» по умолчанию используется во всех фразах, содержащих стоп-слова.
- Оператор «|» (логическое «или»). Позволяет получить статистику одновременно по нескольким условиям. Работает по правилу логического «или».
- Оператор «()» (логическое «и»). Необходим для группировки запросов, а в паре с оператором «|» позволяет создать регулярное выражение и получить список поисковых фраз по комбинации условий.
- Оператор «» (словоформа). В данном случае фиксируется запрос, поэтому из статистики удаляются дополнительные слова. Учитываются различные окончания, стоп-слова, но не учитывается порядок слов.
- Оператор «!» (точное вхождение). Его использование запускает фиксацию словоформы, т.е. будет учтена фраза только с текущим окончанием слов, но не учитывается порядок слов в запросе.
- Оператор «[]» (учет порядка слов). Необходим чтобы зафиксировать порядок слов в запросе. При этом будут учитываться словоформы и стоп-слова.
Как автоматизировать подбор ключевых слов в Вордстате
Даже с помощью плагинов вручную работать с Вордстатом достаточно трудоемко. Но процесс можно автоматизировать. Для этого нам пригодится два инструмента Click.ru:
- Подбор слов и медиапланирование.
- Парсер частотностей Вордстат.
Собираем ключевые слова
Зарегистрируйтесь / авторизуйтесь в Click.ru и откройте инструмент «Подбор слов и медиапланирование».
Укажите базовые данные:
- URL сайта, для которого будете собирать слова;
- место размещения рекламы (поиск, контекстно-медийная сеть или оба варианта).
- регионы, в которых планируете показывать рекламу.
По умолчанию система фиксирует стоп-слова (оператор +, который мы рассматривали выше) и проводит кросс-минусацию. Галочки лучше не снимать.
После указания всех необходимых данных нажмите «Начать новый подбор».
Система проанализирует сайт (URL которого указали на этапе базовых настроек). На основе контента сайта система автоматически подберет релевантные ключевые фразы.
Вы можете добавить к этому списку свои слова или воспользоваться дополнительными инструментами автоматического подбора:
- Слова конкурентов. Здесь нужно будет указать URL сайтов-конкурентов. Система проанализирует их и соберет семантику.
- Слова из счетчиков статистики. Откройте доступ к счетчикам Яндекс.Метрики и/или Google Аналитики. На основе их данных система подберет запросы, по которым к вам на сайт приходили посетители.
Автоматический подборщик слов — это хорошо. Но нам нужны данные Вордстата
Обратите внимание на блок «Ручной подбор слов». Это и есть подборщик на основе данных Вордстата
Как работает подборщик:
1. Введите по одному или списком базовые слова:
Система для каждого слова определяет частотность, а также прогнозы по кликам и бюджету в зависимости от желаемой доли трафика (указываете в столбце «Позиция»).
2. Для просмотра вложенных запросов нажмите на значок списка слева от заданной фразы.
Углубляться можно до тех пор, пока не закончатся вложенные запросы.
3. Просмотрите список подобранных слов. Поставьте галочки на тех, которые вам подходят, и нажмите «Добавить в медиаплан». Вы можете отметить одновременно запросы из ручного и автоматического подборщиков, и добавить в общий список.
Система просчитает бюджет по ключевым словам. Отчет со списком выбранных слов можно скачать в XLSX-формате. При желании можете продолжить настройку — в этом случае система сгенерирует объявления под каждое ключевое слово.
Проверяем частотности Вордстат
С помощью парсера Вордстат можно проверить частотность для списка запросов.
Откройте страницу парсера. Укажите список запросов в поле «Список фраз для проверки»
Также фразы можно загрузить с помощью XLSX-файла (обратите внимание, все запросы должны находиться на первом листе файла, 1 ячейка — 1 запрос)
Далее задайте настройки парсера:
- широкое соответствие;
- оператор «» (фиксирует количество слов в фразе);
- оператор «кавычки» с восклицательным знаком. Фиксирует количество слов в фразе и словоформу каждого слова;
- оператор [] (квадратные скобки). Используется для фиксации порядка слов в фразе.
Поставьте галочки на нужных параметрах (можете проставить галочки на всех четырех). Затем жмите «Запустить проверку». В течение нескольких минут отчет будет готов, и его можно будет скачать в разделе «Список задач».
Отчет скачивается в формате XLSX-файла. Для каждого запроса в таблице указана частотность. Данные по частотности с учетом операторов поиска указаны в отдельных столбцах. Отфильтруйте список и удалите фразы с околонулевой частотностью.
Вот подробный гайд по работе с парсером Вордстат.
Пошаговый алгоритм работы с сервисом:
Создание задачи. Чтобы создать задачу, необходимо перейти во вкладку Wordstat и нажать «Создать новую задачу»
Шаг первый: Поисковая система и регион.
Здесь необходимо ввести название задачи (обязательное поле). Можно ввести любое название, часто бывает удобно вводить название сайта, чтобы в будущем легко найти нужную задачу.
Выберите регион.
Шаг второй: Настройки сбораЗдесь есть два чекбокса от выбора которых, будет зависеть тип задачи:
Сбор ключевых слов из левой колонки Wordstat
Сбор частотности (популярности ключевых слов)
Во вкладке «Сбор ключевых слов из левой колонки Wordstat», где вы указываете количество страниц выдачи Wordstat, по которым пройдет робот. Чем глубже идет робот – тем больше ключевых слов можно получить — «Парсить страниц»
Так же вы можете выбрать «Сбор ключевых слов с правой колонки». В такому случае вы соберете ключевые слова с левой и правой колонки Wordstat Сбор частотности (популярности ключевых слов)
Вы указываете необходимый вам тип частотности
Также здесь есть возможность не собирать частотности ниже заданного предела.
В парсинге вордстата используется умный алгоритм, он обходит ограничения в 7 слов, которое есть при парсинге через Яндекс.Директ (парсинг через Яндекс.Директ использует большинство оптимизаторов при работе в кей коллекторе).
Шаг третий: «Ключевые слова и цена».Загружаем запросы.
Можно загрузить списком либо через файл. Поддерживаемые форматы файла: xls, xlsx. Необходимо указать столбец, из которого должны браться данные, а также учитывать или нет первую строку.
Функционал стоп-слов позволит отфильтровать ваш список и сэкономить время и средства. Вы можете воспользоваться готовым списком стоп-слов — выбрать стоп-слова по тематикам и нужный вам регион.
«Эксперт опции» позаботиться о том, что бы вы не потеряли нужные слова
Обращаем внимание, что по умолчанию применяется символьное соответствие — т.е. стоп-слово «бу» удалит слова и фразы содержащие в себе сочетания букв «бу» — «бублик, бу холодильник, бумага» и т.д
Если выбрать фразовое соответствие стоп-слово «бу» удалит только слово / сочетания слов со словом «бу» — «бу холодильник, купить холодильник бу, бу», но не «бумага, бумеранг» и т.п.
Затем нажимаем «Создать новую задачу».
На странице списка задач виден статус заявки.
Очередь – данные еще не собираются. Сбор данных – счетчик показывает, сколько ключевых слов обработано.На паузе – вы можете вручную поставить задачу на паузу, если не уверены, что хотите его собирать. Или же, задача может сама встать на паузу т.к. у вас кончились деньги на балансе.Готов – и рядом появляется возможность скачать .xlsx файл.
После завершения обработки вы можете сразу отправить файл на кластеризацию.
Экспортный файл имеет вид: 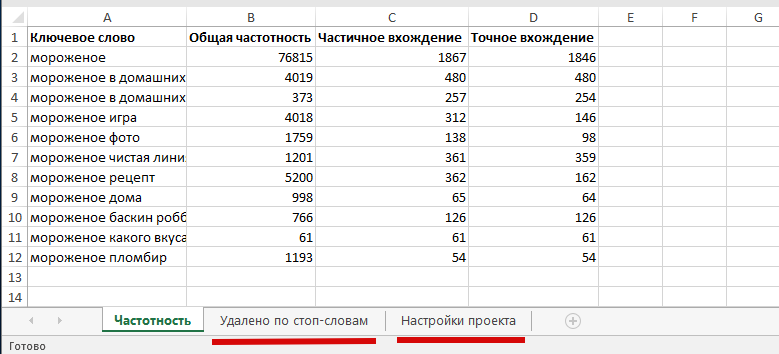
А так же вы можете создать задачи по парсингу Wordstat: сбор левой колонки и проверка частотности через API (api wordstat yandex) — https://www.rush-analytics.ru/api
Оффлайн парсеры
Возможность парсинга Яндекс Вордстат без доступа к интернету или при его низкой скорости – одно из требований к современным инструментам СЕО анализа. Технически это реализовано просто – на компьютер или аналогичное устройство, скачивается базы Wordstat и затем с помощью программы происходит выборка ключевых слов.
Букварикс десктопная версия
Впервые полноценный десктопный вариант представили разработчики «Букварикс». Однако уже в октябре 2017 года этот проект был «заморожен», ПО и базы данных не обновляются. Компания предлагает все инструменты в онлайн-режиме. Скачать приложение можно на старой версии официального сайта, использование бесплатное.
Что нужно учитывать при использовании десктопной версии:
- скачиваемый объем – около 30 Гбайт;
- скачать можно только с Яндекс.Диска, состоит из 20 частей;
- последняя дата обновления БД – 1 октября 2017 г.
Информация в этой версии устарела, возможно использование как вспомогательного инструмента.
Для чего нужен парсинг частотности
Оценка объема трафика по определенным ключевым словам
Частотность в Яндекс.Вордстат отображает количество показов по выбранному ключевому слову за месяц в определенном регионе. С помощью этих данных можно примерно рассчитать потенциальный объем трафика, который можно получать в поисковой выдаче на разных позициях.
Сделать это можно так:
1. Соберите целевую семантику (список ключевиков, по которым вам нужно получать поисковой трафик). Собрать семантику можно с помощью медиапланера от Click.ru.
2. Спарсите частотность ключевых слов. Для примера мы возьмем ключевик «купить Samsung Galaxy в Москве» и проверим его частотность непосредственно в Вордстате. Итого, по данному запросу – 11757 показов в месяц.
3. Найдите в интернете средние значения CTR для каждой из позиций первой страницы поисковой выдачи.
Если ваш сайт добавлен в Яндекс.Вебмастер и работает как минимум несколько месяцев, данные по CTR будут доступны в отчете «Поисковые запросы» → «Все запросы и группы».
К примеру, CTR для второй позиции – 18%. Теперь мы можем посчитать примерный уровень трафика, который можем получить. Формула для расчета:
(Частотность * CTR)/100
Подставляем в формулу наши данные: (11 757 * 18)/100 = 2116.
Конечно, нет гарантии, что мы получим точно такое количество посещений, но для примерной оценки потенциала запроса такие расчеты будут очень полезными.
Еще одна причина для сбора частотности ключей – фильтрация запросов с околонулевой частотностью
Фразы, по которым нет показов (или показов совсем мало – от 1 до 10), лучше убрать из семантического ядра и не тратить время на оптимизацию страниц под такие запросы.
По ним практически не будет трафика, а если запускать контекстную рекламу, объявления получат статус «мало показов» и не будут показываться.
Обратите внимание! Иногда семантику с низкой частотностью не нужно исключать из ядра. Это касается узкоспециализированных тематик, например дорогого медицинского или производственного оборудования
Там ключевые запросы с указанием точной спецификации оборудования могут иметь всего пару запросов в месяц, но приводить максимально целевую и горячую аудиторию.
На что ориентироваться
В зависимости от ниши и типа сайта нижний порог частотности, по которому нужно отсекать бесперспективные запросы, отличается. Для ориентира можете использовать следующие данные:
|
Ниша |
Отсеиваем запросы с частотностью |
|
Узкие тематики |
|
|
Масс-маркет |
до 5 |
|
Информационные ресурсы |
до 30–35 |
При удалении низкочастотных фраз будьте внимательны: НЧ-запросы приводят качественный трафик, поэтому удаляйте фразы аккуратно, оставляя целевые.
Другие возможности сервиса
На всех вкладках Yandex Wordstat есть возможность выполнить сортировку по устройствам: «Десктопы», «Мобильные», «Только телефоны», «Только планшеты». Данный функционал будет полезен, например, при настройке рекламы мобильного приложения в Директе.

Возможность указания региона, в котором вы хотите посмотреть статистику:

С помощью Wordstat также можно посмотреть динамику изменения интереса к запросу на вкладке «История запросов» и количество запросов по регионам на вкладке «По регионам».
История запросов
Как уже говорилось, статистика на вкладке «По словам» отображается за последние 30 дней, поэтому для получения данных за более длительный период необходимо переключиться на вкладку «История запросов», где выводится количество показов по запросу за последние 2 года.

Данную вкладку можно использоваться для первичного анализа сезонности, определения «симптомов» накрутки и оценки динамики интереса к поисковым запросам.
По регионам
На вкладке «По регионам» можно оценить популярность запроса в регионе или городе относительно других, а также получить региональную популярность — долю, которую занимает регион по количеству показов результатов выдачи по данному слову. Другими словами, если популярность более 100%, это означает повышенный интерес к запросу. Чем интерес выше, тем больше процент. И наоборот.

Больше всего купить слона хотят в городе Калуга. Этому факту есть объяснение, попробуйте найти его и вы.

Информация с вкладки может быть использована при планировании контекстной рекламы для принятия решения о необходимости отдельных кампаний под определенный регион.
К сожалению, на этих вкладках не работают операторы Wordstat, поэтому посмотреть данные можно только по широкому типу соответствия.
Как правильно собирать ключевые слова в Вордстат
Вордстат – простой инструмент, с которым вы сможете разобраться меньше, чем за полчаса.
Левая и правая колонка
После введения запроса для проверки в левой колонке вы увидите данные по этому запросу и другим, которые содержат введенный. В правой колонке – похожие:
Учитывайте, что цифра запросов возле верхней строчки левой колонки – это суммарное количество, включающее все нижеследующие запросы.
Правую колонку можно использовать, чтобы увеличить количество релевантных ключевых слов.
Для ускорения подбора слов в Яндекс.Вордстат применяют такие команды:
Поставьте точку возле «по регионам», чтобы просмотреть это:
Тренды и сезонность
Чтобы проверить сезонность, воспользуйтесь «Историей запросов»:
Это поможет своевременно подготовиться к пику в отрасли даже новичку в бизнесе.
С некоторыми поисковыми фразами этот инструмент позволяет найти тренды, то есть те запросы, которых раньше не было в поиске, но которые сейчас набирают популярность:
Если тренд имеет отношение к продажам, количество коммерческих запросов с его использованием также будет увеличиваться.
Поисковые подсказки
Когда запрос становится регулярным, он попадает в поисковые подсказки Яндекса. Точных данных «порога» для этого нет, но это не влияет на полезность этого метода для подбора ключей.
Использовать поисковые подсказки, а не только статистику Яндекс Вордстат стоит, потому что:
- В них быстрее появляются тренды.
- Там можно найти ключи с длинной более 8 слов.
- Не все запросы попадают в Wordstat.
В результате при быстром реагировании на текущие тренды владельцы сайтов получают максимальный трафик по подобным ключевым словам, если своевременно создают необходимые страницы с ответами на запросы пользователей или предугадают последующие запросы.
Коммерческие и информационные ключевые запросы пользователей
Подбор ключевых слов в Вордстат позволяет собрать всевозможные ключевые слова в определенной тематике, но разделить их на коммерческие и информационные – это уже работа для человека, хотя автоматизировать этот процесс также воможно. К коммерческим запросам относятся те, которые содержат слова «сколько стоит», «цена», «купить», «заказать», «с доставкой» и т.д.
Информационные запросы с «своими руками» не подходят для коммерческого продвижения с целью продажи. А вот некоторые другие информационные запросы вполне могут стать гармоничным дополнением к коммерческим.
Операторы сервиса «Подбор Слов»
Для того, чтобы работа в сервисе статистики Яндекса не затягивалась долго и была более точной, существует ряд вспомогательных операторов. Все они используются только в инструменте «По запросам» и вносятся в поле вода поисковой фразы. Рассмотрим каждый оператор по отдельности.
Минус (-)
Оператор предназначен для исключения из списка запросов ненужных слов (так называемые «минус-слова»). Используется в разных случаях, чаще всего для поиска запросов СЯ для коммерческих проектов. Например, сравните левые колонки Вордстата по запросу «внутренняя перелинковка». В первом случае обычная фраза, во втором — исключены запросы со словом «страница»:
Замечу, что минусовали мы в примере слово «страница». В итоге Вордстат исключил все варианты слова с любым падежом.
Плюс (+)
С помощью оператора «плюс» мы принудительно ставим указание сервису на проверку запроса с предлогами и союзами (без этого оператора они исключаются). Вот пример работы этого оператора:
Как видим из примера, в первом случае число запросов с фразой «как готовить омлет из яиц» было самым большим — 712. Это тоже самое, если бы мы набирали запрос в Вордстате — «готовить омлет яиц». Во втором случае число запросов стало меньше, так как мы захотели увидеть их с учетом предлога «из». В третьем их стало еще меньше — появилось слово «как».
В Вордстате по умолчанию при вводе запроса без плюсов в левой колонке дается значение именно с плюсами:
Или и группировка | ()
Оператор «или» позволяет собрать поисковые запросы, слова которых могут иметь разное написание, но одинаковое значение. Например, нам нужны все запросы по созданию блюда «омлет». Для этого мы возьмем сборку трех одинаковых по смыслу словосочетания:
В итоге в левой колонке мы получим все запросы по этим трем фразам.
Ту же самую задачу можно решить, если использовать оператор «группировка». В этом случае нам не нужно будет писать три раза слово «омлет»:
Итак, оператор «или» позволяет нам указать в искомой фразе варианты каких-то слов. Если слов с вариантами несколько, используется «группировка». В итоге получается максимально возможная подборка запросов. Например:
Кавычки («»), восклицательный знак (!)
Используя данный оператор, при подсчете запросов для левой колонки, Вордстат будет считать показы только этой фразы. При подсчете будут также учитываться различные словоформы фразы, а также разный порядок слов. Например, вот какую нам статистику предложит Вордстат по запросу «весенняя капель»:
Оператор «восклицательный знак» учитывает показы по форме слова, которую мы указали, без каких-то изменений (не учитываются различные словоформы):
Небольшое замечание — восклицательный знак ставиться непосредственно перед словом, пробел между оператором «!» и словом не ставится.
В поисковом продвижении используется совместная связка этих операторов. Число показов искомой фразы с этими операторами называется «точной частотой (частотностью) запроса»:
При таком построении искомой фразы с помощью этих операторов мы можем подсчитать запросы, которые не могут менять как сам запрос, так и его словоформы (например, окончания). Это позволит нам с учетом кликабельности сниппета дать примерное число показов продвигаемой страницы по этому запросу в Яндексе (в зависимости от занимаемого места в топе).
Именно поэтому при составлении семантического ядра мы обращаем внимание на точную частотность запроса.
Благодаря специальным операторам, мы можем в Вордстате узнать нужные нам запросы и число их показов практически по любым нашим требованиям. Например, нам нужны запросы по рецептуре блинов с такими ограничениями:
- в запросах должны быть слова «рецепт» и «приготовить»;
- берем разные варианты по типу блюда (блины, блинчики);
- в запросах нет ингредиента «молоко»;
- хотим запросы, чтобы было там точное слово «кефир».
В итоге у нас получается запрос со следующими операторами и соответствующим списком найденных фраз:
Яндекс Вордстат — ключевые моменты
При игнорировании служебных команд Yandex Wordstat не отображает точное количество показов по заданной фразе. На это указывает фраза «Что искали со словом…», подразумевающая, что вместе с заданным Яндекс запросом отобразились запросы, в которых встречаются указанные ключевые слова.
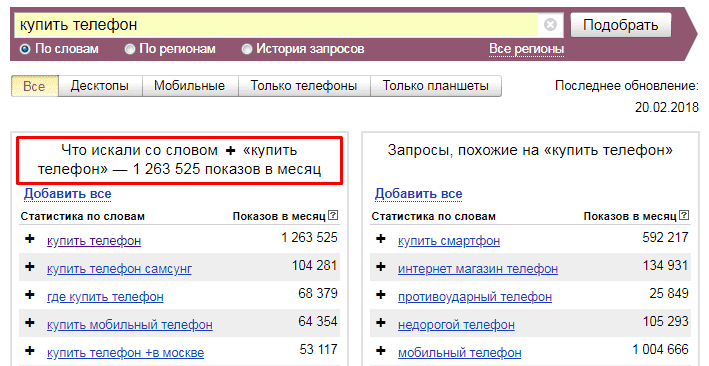
Для уточнения запросов в Яндексе применяются специальные символы и операторы.
Операторы Яндекса
Оператор «-» — предоставляет возможность исключить слова.
Оператор «+» — направлен на принудительное использование слова.
Оператор кавычки «» — отображает данные статистики исключительно для одного слова, без участия в иных сочетаниях.
Оператор «!» — предназначен для вывода статистических данных в точном вхождении.
Допустим, стоит задача определить количество запросов по конкретной ключевой фразе. В таком случае используйте операторы «» и!. Поместив запрос в кавычки, вы зададите команду показывать в результате выдачи только те слова и словосочетания, которые заключены в кавычки.
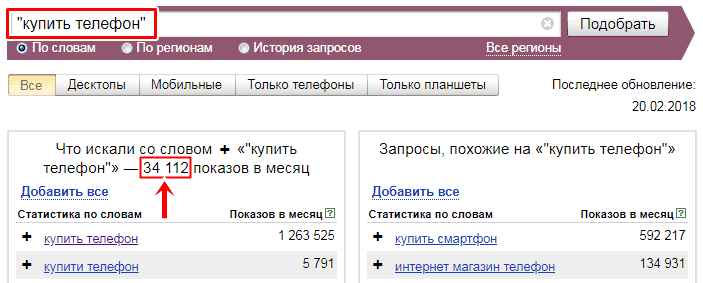
С помощью восклицательного знака предоставляется возможность исключить все ненужные словоформы. Для этого достаточно заключить Яндекс запрос в кавычки и перед каждым словом поставить восклицательный знак.
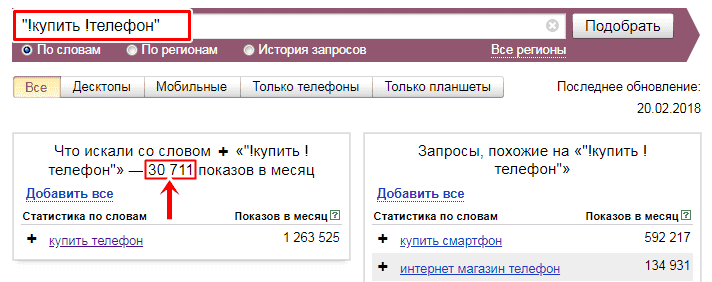
Итог
Подобрать ключевые слова для статьи не так уж и сложно и Яндекс Вордстат в этом деле станет незаменимым помощником. Не забывайте пользоваться операторами, которые позволят получить более конкретные данные по частоте использования интересующих вас запросов, что позволит подобрать наиболее релевантные ключевики.
Как найти популярные ключевые слова в Яндексе
В примере ниже рассмотрим, как находить популярные ключевые фразы, которые чаще спрашиваются и имеют правильную форму. Имея эти данные, их можно проверять по статистике ключевых слов.
Если Вас интересуют конкретные популярные слова в виде “рейтинг запросов в яндексе”, то скорее всего – эти данные в открытом виде, найти будет сложно. Но на самом деле, есть некоторые способы узнать о самых популярных словах. На помощь, могут прийти данные статистики Liveinternet и конечно же Гугл Тренды. Об этих инструментах, мы поговорим чуть ниже.
И кстати! В официальном блоге Яндекса или Твиттере Yandex, иногда публикуются популярные направления, что люди искали чаще всего. Обычно, эти данные предоставляют в виде постера. Например:

…или другой пример – новые слова на поиске, набирающие популярность: